Worksharing Constructs(others)
Most of the time, we end up having more than one loop, a nested loop, where two or three loops will be next to each other. OpenMP provides a clause for handling this kind of situation with collapse. To understand this, we will now study Matrix multiplication, which involves a nested loop. Again, most of the time, we might do computation with a nested loop. Therefore, studying this example would be good practice for solving the nested loop in the future.
Collapse¶
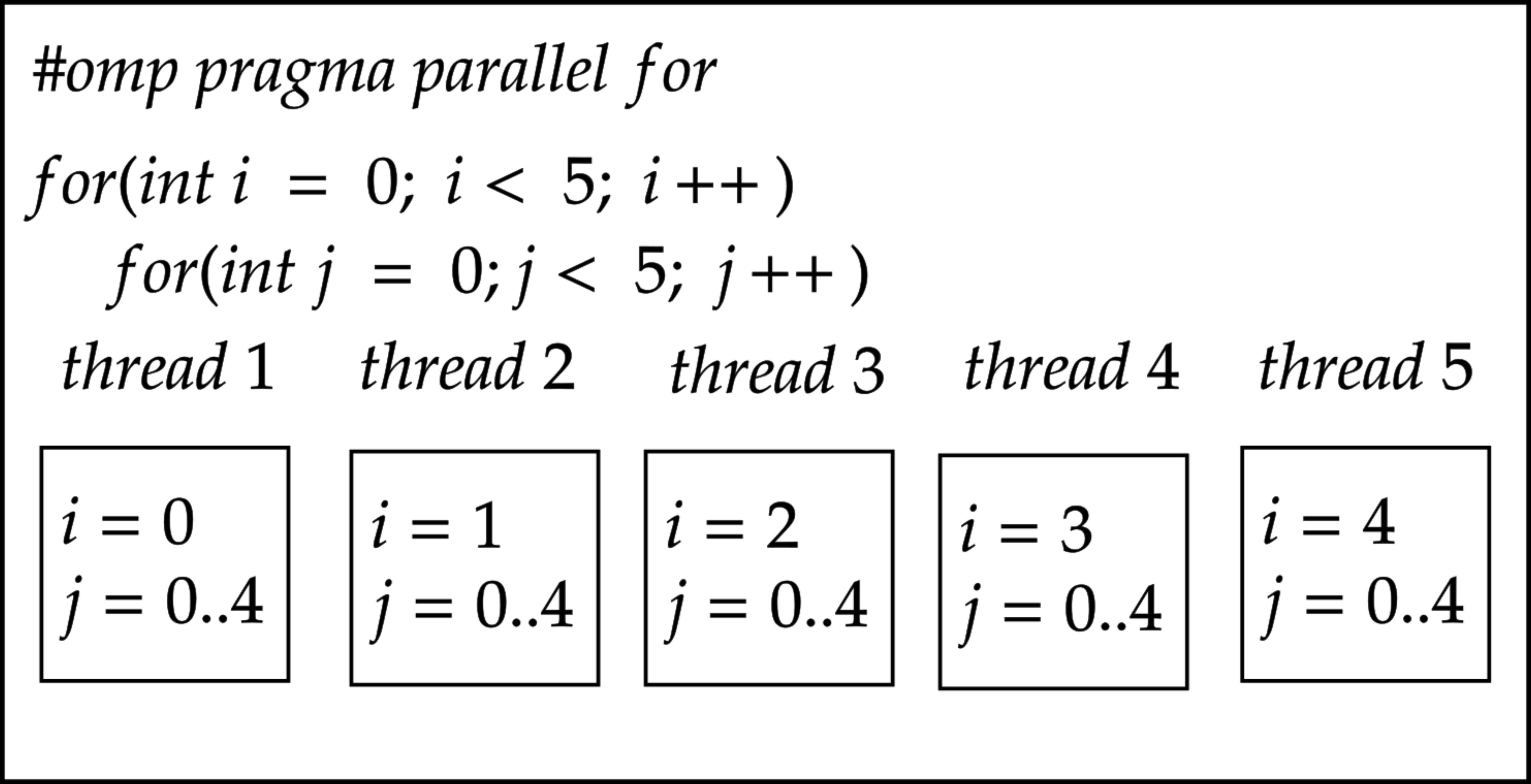
The collapse clause can be used for the nested loop; an entire part of the iteration will be divided by an available number of threads. If the outer loop is equal to the available threads, then the outer loop will be divided by the number of threads. The figure below shows an example of not using the collapse clause. Therefore, only the outer loop is parallelised; each outer loop index will have N number of inner loop iterations.
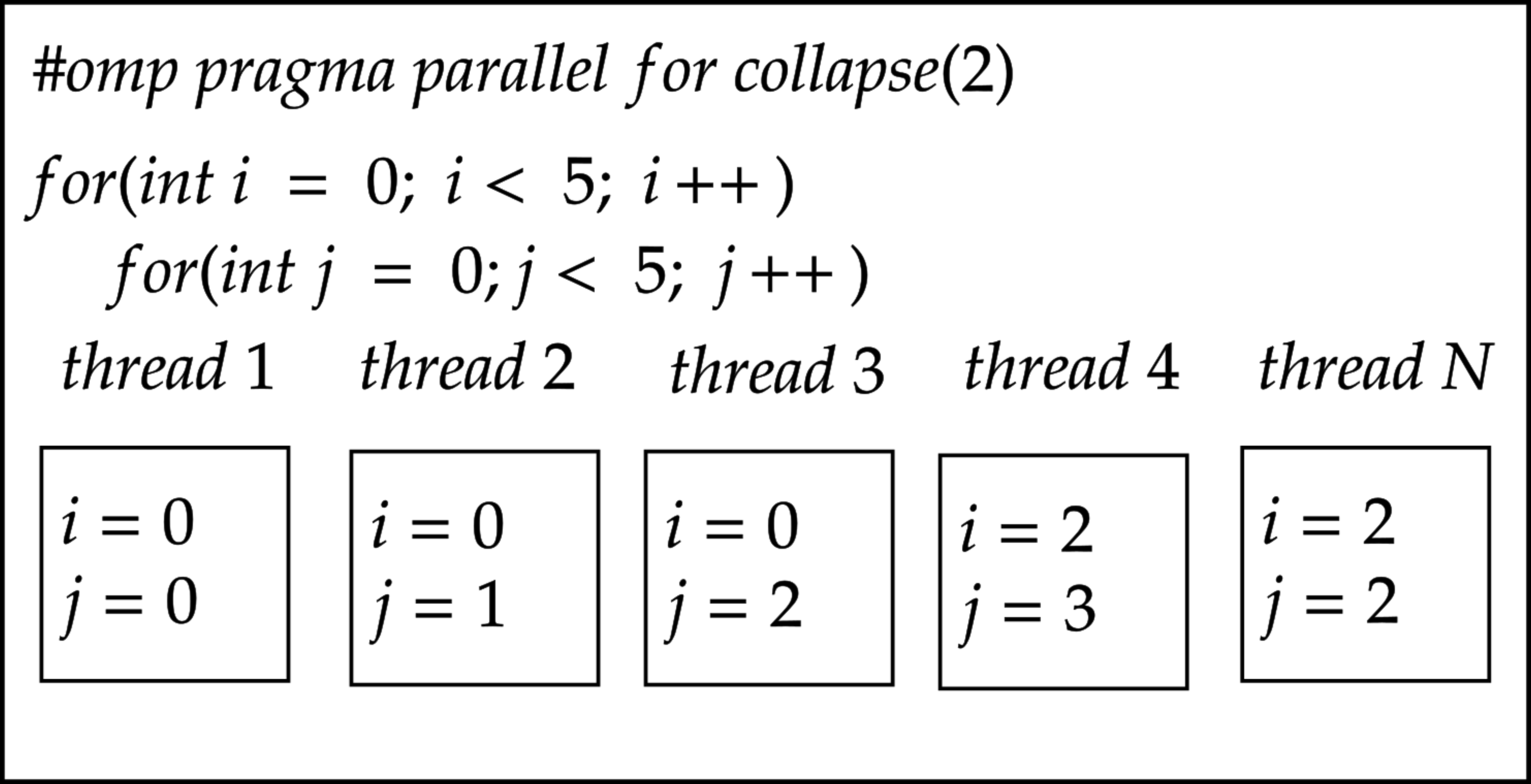
This is not what we want. Instead, with the available threads, we would like to parallelise the loops as efficiently as we could. Moreover, most of the time, we might have more threads available on a machine; for example, on MeluXina, we can have up to 256 threads. Therefore, when adding the collapse clause, we notice that the available threads execute every single iteration, as seen in the figure below.
Collapse
#pragma omp parallel
#pragma omp for collapse(2)
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
cout << " Thread id" << " " << omp_get_thread_num() << endl;
}
}
// Or
#pragma omp parallel for collapse(2)
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
cout << " Thread id" << " " << omp_get_thread_num() << endl;
}
}
Examples and Questions: Collapse
#include <iostream>
#include <omp.h>
using namespace std;
int main()
{
int N=5;
#pragma omp parallel
#pragma omp for collapse(2)
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
cout << "Outer loop id " << i << " Inner loop id "<< j << " Thread id" << " " << omp_get_thread_num() << endl;
}
}
return 0;
}
Outer loop id 4 Inner loop id 2 Thread id 16
Outer loop id 1 Inner loop id 4 Thread id 3
Outer loop id 5 Inner loop id 1 Thread id 20
Outer loop id 4 Inner loop id 1 Thread id 15
Outer loop id 2 Inner loop id 1 Thread id 5
Outer loop id 3 Inner loop id 1 Thread id 10
Outer loop id 3 Inner loop id 4 Thread id 13
Outer loop id 4 Inner loop id 4 Thread id 18
Outer loop id 4 Inner loop id 3 Thread id 17
Outer loop id 3 Inner loop id 3 Thread id 12
Outer loop id 1 Inner loop id 2 Thread id 1
Outer loop id 2 Inner loop id 3 Thread id 7
Outer loop id 1 Inner loop id 5 Thread id 4
Outer loop id 2 Inner loop id 2 Thread id 6
Outer loop id 3 Inner loop id 2 Thread id 11
Outer loop id 2 Inner loop id 5 Thread id 9
Outer loop id 3 Inner loop id 5 Thread id 14
Outer loop id 5 Inner loop id 3 Thread id 22
Outer loop id 5 Inner loop id 4 Thread id 23
Outer loop id 5 Inner loop id 5 Thread id 24
Outer loop id 2 Inner loop id 4 Thread id 8
Outer loop id 1 Inner loop id 3 Thread id 2
Outer loop id 4 Inner loop id 5 Thread id 19
Outer loop id 1 Inner loop id 1 Thread id 0
Outer loop id 5 Inner loop id 2 Thread id 21
- Can you add any of the scheduling clauses here, such as static, dynamic, etc.?
- Is it really necessary to them when you use the
collapse, or is it dependent on other factors, such as the nature of the computation and available threads?
Reduction¶
The reduction clauses are data-sharing attribute clauses that can be used to perform some forms of repetition calculations in the parallel region.
- it can be used for arithmetic reductions: +,*,-,max,min
- and also with logical operator reductions in C: & && | || ˆ
Reduction
Examples and Question: Reduction
program main
use omp_lib
implicit none
! Input vectors
real(8), dimension(:), allocatable :: a
integer :: n, i, sum
n=10
! Allocate memory for vector
allocate(a(n))
!$omp parallel do reduction(+:sum)
do i = 1, n
a(i) = i
sum = sum + a(i)
end do
!$omp end parallel do
print *, 'Sum is ', sum
end program main
- What happens if you do not use the reduction clause? Do we still get the correct answer?
Matrix Multiplication¶
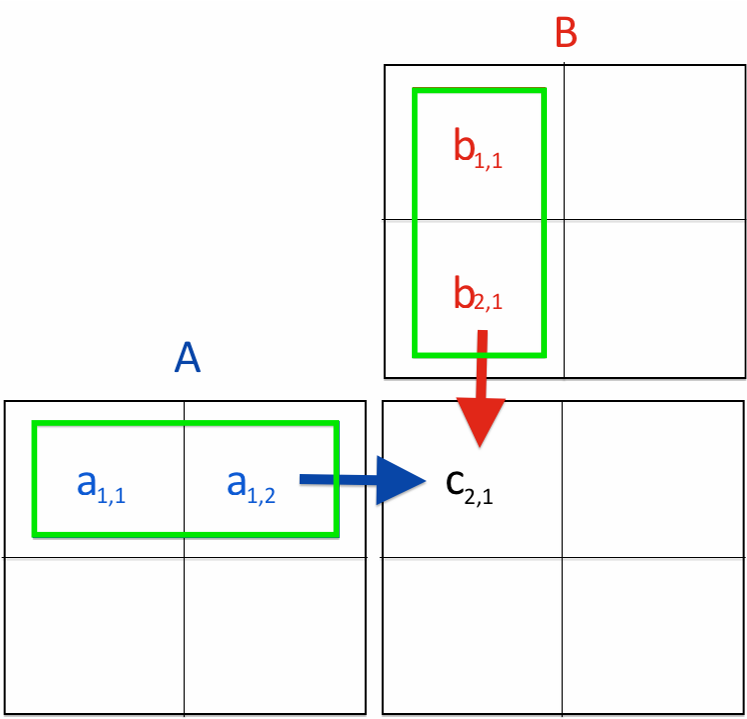
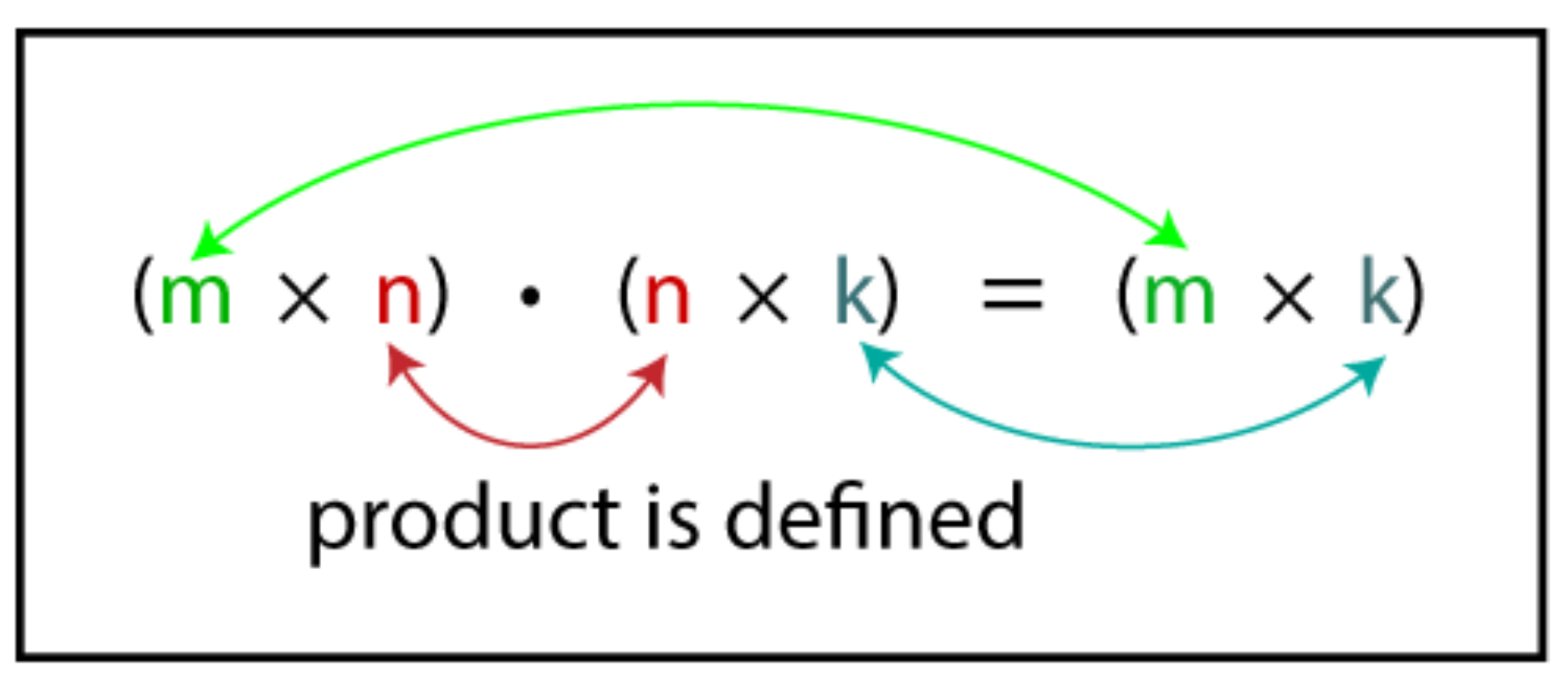
In this example, we consider a square matrix; M=N is equal for both A and B matrices. Even though we deal here with a 2D matrix, we create a 1D array to represent a 2D matrix. In this example, we must use the collapse clause since matrix multiplication deals with 3 loops. The first 2 outer loops will take rows of the A matrix and columns of the B matrix. Therefore, these two loops can be easily parallelised.
matrix multiplication function call
Questions and Solutions¶
Examples: Matrix Multiplication
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
void Matrix_Multiplication(float *a, float *b, float *c, int width)
{
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float sum=0;
for(int i = 0; i < width ; ++i)
{
sum += a[row*width+i] * b[i*width+col];
}
c[row*width+col] = sum;
}
}
}
int main()
{
printf("Programme assumes that matrix size is N*N \n");
printf("Please enter the N size number \n");
int N =0;
scanf("%d", &N);
// Initialize the memory
float *a, *b, *c;
// Allocate memory
a = (float*)malloc(sizeof(float) * (N*N));
b = (float*)malloc(sizeof(float) * (N*N));
c = (float*)malloc(sizeof(float) * (N*N));
// Initialize arrays
for(int i = 0; i < (N*N); i++)
{
a[i] = 1.0f;
b[i] = 2.0f;
}
// Fuction call
clock_t start = clock();
Matrix_Multiplication(a, b, c, N);
clock_t end = clock();
double elapsed = (double)(end - start)/CLOCKS_PER_SEC;
printf("Time measured: %.3f seconds.\n", elapsed);
// Verification
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
printf("%f ", c[j]);
}
printf("\n");
}
// Deallocate memory
free(a);
free(b);
free(c);
return 0;
}
module Matrix_Multiplication_Mod
implicit none
contains
subroutine Matrix_Multiplication(a, b, c, width)
use omp_lib
! Input vectors
real(8), intent(in), dimension(:) :: a
real(8), intent(in), dimension(:) :: b
real(8), intent(out), dimension(:) :: c
integer :: i, row, col, width
do row = 0, width-1
do col = 0, width-1
real(8) :: sum
sum=0
do i = 0, width-1
sum = sum + (a((row*width)+i+1) * b((i*width)+col+1))
enddo
c(row*width+col+1) = sum
enddo
enddo
end subroutine Matrix_Multiplication
end module Matrix_Multiplication_Mod
program main
use Matrix_Multiplication_Mod
use omp_lib
implicit none
! Input vectors
real(8), dimension(:), allocatable :: a
real(8), dimension(:), allocatable :: b
! Output vector
real(8), dimension(:), allocatable :: c
! real(8) :: sum = 0
integer :: n, i
print *, "This program does the addition of two vectors "
print *, "Please specify the vector size = "
read *, n
! Allocate memory for vector
allocate(a(n*n))
allocate(b(n*n))
allocate(c(n*n))
! Initialize content of input vectors,
! vector a[i] = sin(i)^2 vector b[i] = cos(i)^2
do i = 1, n*n
a(i) = sin(i*1D0) * sin(i*1D0)
b(i) = cos(i*1D0) * cos(i*1D0)
enddo
! Call the vector addition subroutine
call Matrix_Multiplication(a, b, c, n)
!!Verification
do i=1,n*n
print *, c(i)
enddo
! Delete the memory
deallocate(a)
deallocate(b)
deallocate(c)
end program main
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
void Matrix_Multiplication(float *a, float *b, float *c, int width)
{
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float sum=0;
for(int i = 0; i < width ; ++i)
{
sum += a[row*width+i] * b[i*width+col];
}
c[row*width+col] = sum;
}
}
}
int main()
{
printf("Programme assumes that matrix size is N*N \n");
printf("Please enter the N size number \n");
int N =0;
scanf("%d", &N);
// Initialize the memory
float *a, *b, *c;
// Allocate memory
a = (float*)malloc(sizeof(float) * (N*N));
b = (float*)malloc(sizeof(float) * (N*N));
c = (float*)malloc(sizeof(float) * (N*N));
// Initialize arrays
for(int i = 0; i < (N*N); i++)
{
a[i] = 1.0f;
b[i] = 2.0f;
}
// Function call
Matrix_Multiplication(a, b, c, N);
// Verification
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
printf("%f ", c[j]);
}
printf("\n");
}
// Deallocate memory
free(a);
free(b);
free(c);
return 0;
}
module Matrix_Multiplication_Mod
implicit none
contains
subroutine Matrix_Multiplication(a, b, c, width)
use omp_lib
! Input vectors
real(8), intent(in), dimension(:) :: a
real(8), intent(in), dimension(:) :: b
real(8), intent(out), dimension(:) :: c
integer :: i, row, col, width
!!! ADD LOOP PARALLELISATION
do row = 0, width-1
do col = 0, width-1
real(8) :: sum
sum=0
do i = 0, width-1
sum = sum + (a((row*width)+i+1) * b((i*width)+col+1))
enddo
c(row*width+col+1) = sum
enddo
enddo
end subroutine Matrix_Multiplication
end module Matrix_Multiplication_Mod
program main
use Matrix_Multiplication_Mod
use omp_lib
implicit none
! Input vectors
real(8), dimension(:), allocatable :: a
real(8), dimension(:), allocatable :: b
! Output vector
real(8), dimension(:), allocatable :: c
! real(8) :: sum = 0
integer :: n, i
print *, "This program does the addition of two vectors "
print *, "Please specify the vector size = "
read *, n
! Allocate memory for vector
allocate(a(n*n))
allocate(b(n*n))
allocate(c(n*n))
! Initialize content of input vectors,
! vector a[i] = sin(i)^2 vector b[i] = cos(i)^2
do i = 1, n*n
a(i) = sin(i*1D0) * sin(i*1D0)
b(i) = cos(i*1D0) * cos(i*1D0)
enddo
!!!! ADD PARALLEL REGION
! Call the vector addition subroutine
call Matrix_Multiplication(a, b, c, n)
!!Verification
do i=1,n*n
print *, c(i)
enddo
! Delete the memory
deallocate(a)
deallocate(b)
deallocate(c)
end program main
#include<stdio.h>
#include<stdlib.h>
#include<omp.h>
void Matrix_Multiplication(float *a, float *b, float *c, int width)
{
#pragma omp for collapse(2)
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float sum=0;
for(int i = 0; i < width ; ++i)
{
sum += a[row*width+i] * b[i*width+col];
}
c[row*width+col] = sum;
}
}
}
int main()
{
printf("Programme assumes that matrix size is N*N \n");
printf("Please enter the N size number \n");
int N =0;
scanf("%d", &N);
// Initialize the memory
float *a, *b, *c;
// Allocate memory
a = (float*)malloc(sizeof(float) * (N*N));
b = (float*)malloc(sizeof(float) * (N*N));
c = (float*)malloc(sizeof(float) * (N*N));
// Initialize arrays
for(int i = 0; i < (N*N); i++)
{
a[i] = 1.0f;
b[i] = 2.0f;
}
omp_set_num_threads(omp_get_max_threads());
// Function call
double start = omp_get_wtime();
#pragma omp parallel
Matrix_Multiplication(a, b, c, N);
ouble end = omp_get_wtime();
printf("Time measured: %.3f seconds.\n", end - start);
// Verification
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
printf("%f ", c[j]);
}
printf("\n");
}
// Deallocate memory
free(a);
free(b);
free(c);
return 0;
}
module Matrix_Multiplication_Mod
implicit none
contains
subroutine Matrix_Multiplication(a, b, c, width)
use omp_lib
! Input vectors
real(8), intent(in), dimension(:) :: a
real(8), intent(in), dimension(:) :: b
real(8), intent(out), dimension(:) :: c
integer :: i, row, col, width
!$omp do collapse(2)
do row = 0, width-1
do col = 0, width-1
real(8) :: sum
sum=0
do i = 0, width-1
sum = sum + (a((row*width)+i+1) * b((i*width)+col+1))
enddo
c(row*width+col+1) = sum
enddo
enddo
!$omp end do
end subroutine Matrix_Multiplication
end module Matrix_Multiplication_Mod
program main
use Matrix_Multiplication_Mod
use omp_lib
implicit none
! Input vectors
real(8), dimension(:), allocatable :: a
real(8), dimension(:), allocatable :: b
! Output vector
real(8), dimension(:), allocatable :: c
! real(8) :: sum = 0
integer :: n, i
print *, "This program does the addition of two vectors "
print *, "Please specify the vector size = "
read *, n
! Allocate memory for vector
allocate(a(n*n))
allocate(b(n*n))
allocate(c(n*n))
! Initialize content of input vectors,
! vector a[i] = sin(i)^2 vector b[i] = cos(i)^2
do i = 1, n*n
a(i) = sin(i*1D0) * sin(i*1D0)
b(i) = cos(i*1D0) * cos(i*1D0)
enddo
!$omp parallel
! Call the vector addition subroutine
call Matrix_Multiplication(a, b, c, n)
!$omp end parallel
!!Verification
do i=1,n*n
print *, c(i)
enddo
! Delete the memory
deallocate(a)
deallocate(b)
deallocate(c)
end program main
Compilation and Output
Questions
- Right now, we are dealing with square matrices. Could you write a code for a different matrix size while still fulfilling the matrix multiplication condition?
Could you use any one of the loop scheduling methods, such as dynamic or static? Do you see any performance gain?