Compute Constructs and Paralleize Loops
Compute Constructs¶
In this initial exercise, we will explore the process of offloading computational tasks to a device, specifically the GPU (Graphics Processing Unit). The primary objective of OpenACC is to streamline this offloading using its dedicated APIs.
OpenACC offers two primary constructs for offloading computations to the GPU, which we will discuss in detail:
-
Parallel Construct (
parallel): This construct allows for the parallelization of computations across multiple processing units. It is a suitable choice for programmers who possess a strong understanding of their code's parallel behavior. -
Kernels Construct (
kernels): This alternative also enables parallelization but provides greater control over the parallel region. It is generally recommended for programmers who may not be as familiar with the intricacies of parallel execution, as the compiler will manage the complexities of safe parallelization within this construct.
Both constructs serve similar purposes in facilitating computation on the GPU; however, the choice between them depends on the programmer's comfort level with parallel programming. If you have significant experience and knowledge of the computations being executed in parallel, you may opt for the parallel construct. In contrast, for those who prefer a more managed approach to ensure safety and correctness in parallel execution, using kernels is advisable.
To effectively utilize OpenACC constructs, clauses, and environment variables, it is essential to include the OpenACC library in your code. This inclusion enables access to the full range of OpenACC features and functionalities.
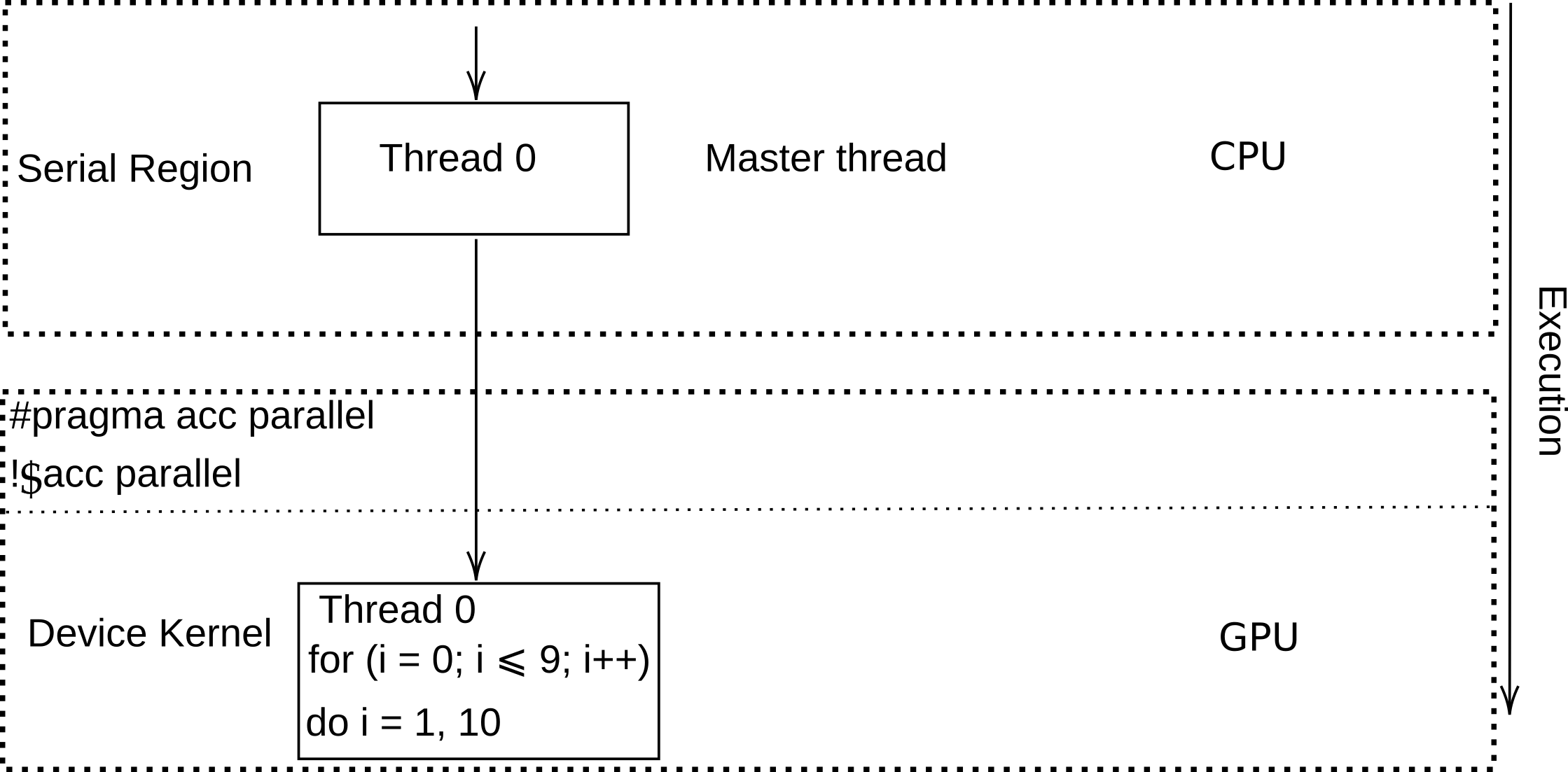
To create a parallel region in OpenACC, we utilize the following compute constructs:
Parallel Constructs
Available clauses for parallel
async [ ( int-expr ) ]
wait [ ( int-expr-list ) ]
num_gangs( int-expr )
num_workers( int-expr )
vector_length( int-expr )
device_type( device-type-list )
if( condition )
self [ ( condition ) ]
reduction( operator : var-list )
copy( var-list )
copyin( [ readonly: ] var-list )
copyout( [ zero: ] var-list )
create( [ zero: ] var-list )
no_create( var-list )
present( var-list )
deviceptr( var-list )
attach( var-list )
private( var-list )
firstprivate( var-list )
default( none | present )
Kernels Constructs
Available clauses for kernels
async [ ( int-expr ) ]
wait [ ( int-expr-list ) ]
num_gangs( int-expr )
num_workers( int-expr )
vector_length( int-expr )
device_type( device-type-list )
if( condition )
self [ ( condition ) ]
copy( var-list )
copyin( [ readonly: ] var-list )
copyout( [ zero: ] var-list )
create( [ zero: ] var-list )
no_create( var-list )
present( var-list )
deviceptr( var-list )
attach( var-list )
default( none | present )
Compilers Supporting OpenACC Programming Model¶
The following compilers provide support for the OpenACC programming model, which facilitates the development of parallel applications across various architectures:
- GNU Compiler Collection (GCC): This is an open-source compiler that supports both Nvidia and AMD CPUs, making it a versatile choice for developers looking to implement OpenACC.
- Nvidia HPC SDK: Developed by Nvidia, this compiler is specifically optimized for Nvidia GPUs. It offers robust support for the OpenACC programming model, enabling efficient utilization of GPU resources.
- HPE Compiler: Currently, this compiler supports FORTRAN but does not have support for C/C++. It is designed for high-performance computing applications and works well with the OpenACC model.
Examples (GNU, Nvidia HPC SDK and HPE): Compilation
Questions and Solutions¶
Examples: Hello World
Compilation and Output
Loop¶
In our second exercise, we will delve into the principles of loop parallelization, a crucial technique in high-performance computing that significantly enhances the efficiency of intensive computations. When dealing with computationally heavy operations within loops, it is often advantageous to parallelize these loops to leverage the full capabilities of multi-core processors or GPUs.
To illustrate this concept, we will begin with a straightforward example: printing Hello World from GPU multiple times. This will serve as a basis for understanding how to implement loop parallelization effectively.
It is important to note that simply adding directives such as #pragma acc parallel or #pragma acc kernels is insufficient for achieving parallel execution of computations. These directives are primarily designed to instruct the compiler to execute the computations on the device, but additional considerations and structure are required to fully exploit parallelization. Understanding how to appropriately organize and optimize loops for parallel execution is essential for maximizing performance in computational tasks.
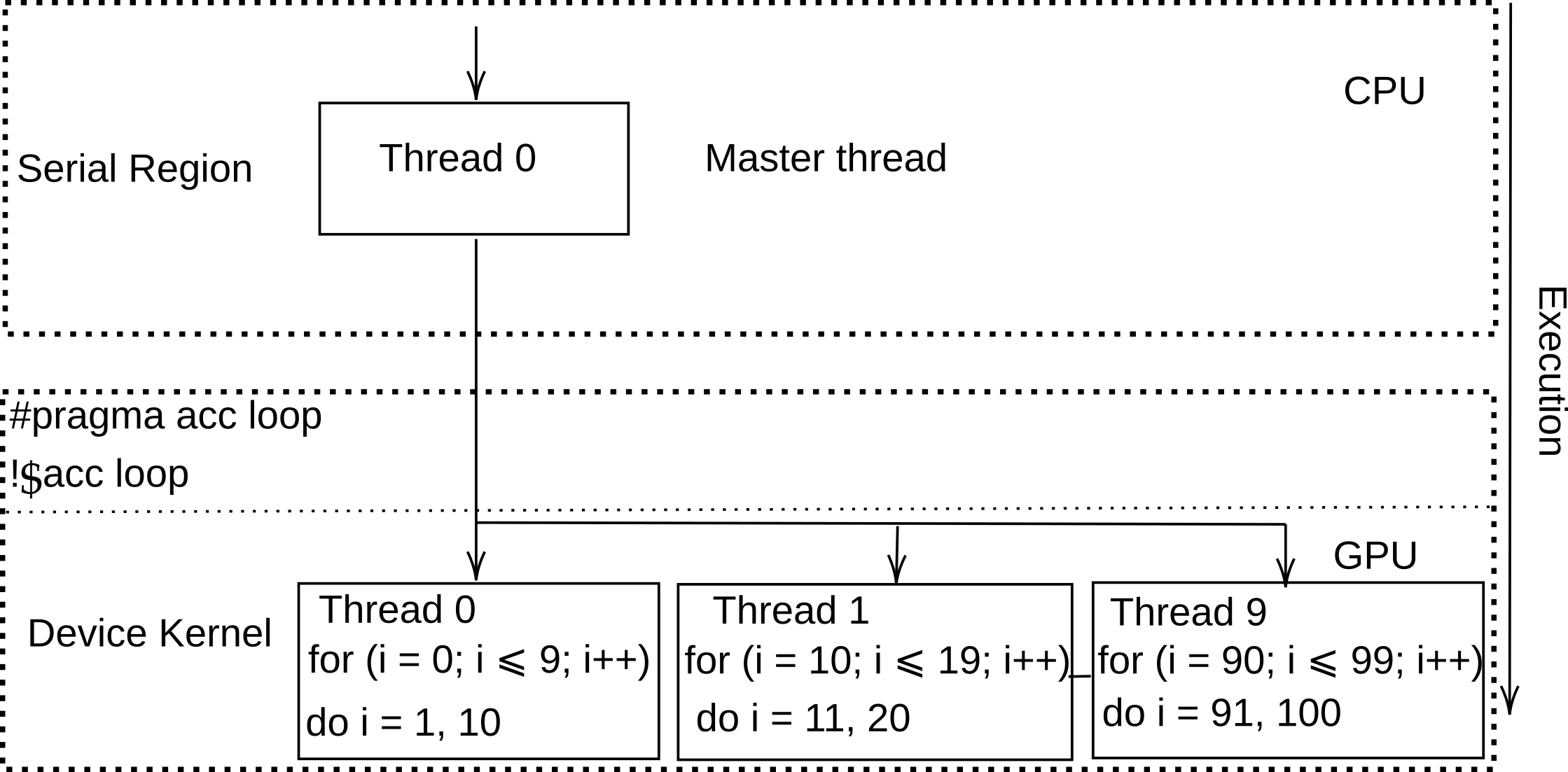
Available clauses for loop
Questions and Solutions¶
Examples: Loop (Hello World)
Compilation and Output
// compilation
$ nvc -fast -acc=gpu -gpu=cc80 -Minfo=accel Hello-world-parallel-loop.c -o Hello-World-GPU
main:
5, Generating NVIDIA GPU code
7, #pragma acc loop gang /* blockIdx.x */
// execution
$ ./Hello-World-GPU
// output
$ Hello World from GPU!
$ Hello World from GPU!
$ Hello World from GPU!
$ Hello World from GPU!
$ Hello World from GPU!
// compilation
$ nvc -fast -acc=gpu -gpu=cc80 -Minfo=accel Hello-world-kernels-loop.c -o Hello-World-GPU
main:
7, Loop is parallelizable
Generating NVIDIA GPU code
7, #pragma acc loop gang, vector(32) /* blockIdx.x threadIdx.x */
// execution
$ ./Hello-World-GPU
// output
$ Hello World from GPU!
$ Hello World from GPU!
$ Hello World from GPU!
$ Hello World from GPU!
$ Hello World from GPU!
Created: September 18, 2023 13:12:23