Work Sharing Constructs(loop)
Serial version discussion¶
To begin to understand the work-sharing constructs, we need to learn how to parallelise the for - C/C++ or do - FORTRAN loop. For this, we will learn simple vector addition examples.
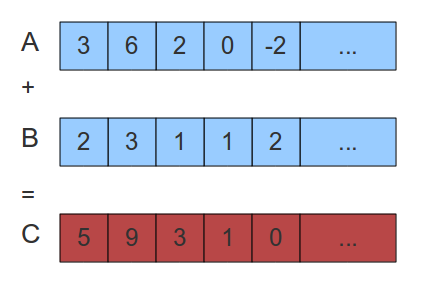
As we can see from the above figure, the two vectors should be added to get a single vector. This is done by iterating over the elements and adding them together. For this, we use for - C/C++ or do - FORTRAN. Since there are no data dependencies, the loop indexes do not have any data dependency on the other indexes. Therefore, it is easy to parallelise.
Examples: Loop
Parallel version discussion¶
Now we will look into the how to parallelise the for - C/C++ or do - FORTRAN loops. For this, we just need to add below syntax (OpenMP directives).
| Functionality | Syntax in C/C++ | Syntax in FORTRAN |
|---|---|---|
| Distribute iterations over the threads | #pragma omp for | !$omp do |
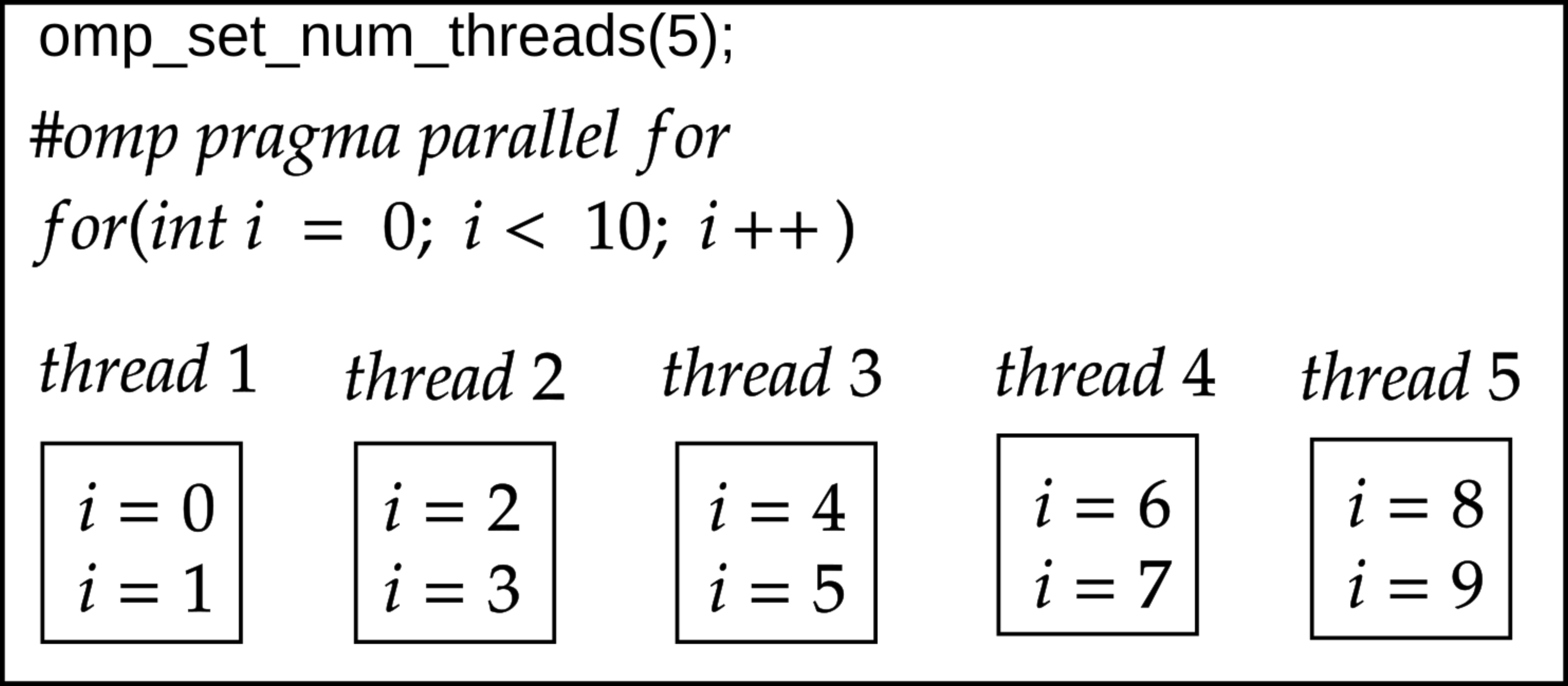
With the help of the above syntax, the loops can be easily parallelised. The figure below shows an example of how the loops are parallelised. As we can notice here, we set the omp_set_num_threads(5) for the number of parallel threads that should be used within the loops. Furthermore, the loop index goes from 0 to 9; in total, we need to iterate 10 elements.
In this example, using 5 threads would divide 10 iterations by two. Therefore, each thread will handle 2 iterations. In total, 5 threads will do just 2 iterations in parallel for 10 elements.
Examples: Loops parallelisation
From understating loop parallelisation, we will continue with vector operations in parallel, that is, adding two vectors. It is very simple, and we just need to add the #pragma omp parallel for for C/C++, !$omp parallel do for FORTRAN. Could you please try this yourself? The serial code, templates, and compilation command have been provided below.
Questions and Solutions¶
Examples: Vector Addition
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <assert.h>
#include <time.h>
#define N 5120 // 500000000
#define MAX_ERR 1e-6
// CPU function that adds two vector
float * Vector_Add(float *a, float *b, float *c, int n)
{
for(int i = 0; i < n; i ++)
{
c[i] = a[i] + b[i];
}
return c;
}
int main()
{
// Initialize the variables
float *a, *b, *c;
// Allocate the memory
a = (float*)malloc(sizeof(float) * N);
b = (float*)malloc(sizeof(float) * N);
c = (float*)malloc(sizeof(float) * N);
// Initialize the arrays
for(int i = 0; i < N; i++)
{
a[i] = 1.0f;
b[i] = 2.0f;
}
// Start measuring time
clock_t start = clock();
// Executing vector addition function
Vector_Add(a, b, c, N);
// Stop measuring time and calculate the elapsed time
clock_t end = clock();
double elapsed = (double)(end - start)/CLOCKS_PER_SEC;
printf("Time measured: %.3f seconds.\n", elapsed);
// Verification
for(int i = 0; i < N; i++)
{
assert(fabs(c[i] - a[i] - b[i]) < MAX_ERR);
}
printf("c[0] = %f\n", c[0]);
printf("PASSED\n");
// Deallocate the memory
free(a);
free(b);
free(c);
return 0;
}
module Vector_Addition_Mod
implicit none
contains
subroutine Vector_Addition(a, b, c, n)
! Input vectors
real(8), intent(in), dimension(:) :: a
real(8), intent(in), dimension(:) :: b
real(8), intent(out), dimension(:) :: c
integer :: i, n
do i = 1, n
c(i) = a(i) + b(i)
end do
end subroutine Vector_Addition
end module Vector_Addition_Mod
program main
use Vector_Addition_Mod
implicit none
! Input vectors
real(8), dimension(:), allocatable :: a
real(8), dimension(:), allocatable :: b
! Output vector
real(8), dimension(:), allocatable :: c
! real(8) :: sum = 0
integer :: n, i
print *, "This program does the addition of two vectors "
print *, "Please specify the vector size = "
read *, n
! Allocate memory for vector
allocate(a(n))
allocate(b(n))
allocate(c(n))
! Initialize content of input vectors,
! vector a[i] = sin(i)^2 vector b[i] = cos(i)^2
do i = 1, n
a(i) = sin(i*1D0) * sin(i*1D0)
b(i) = cos(i*1D0) * cos(i*1D0)
enddo
! Call the vector addition subroutine
call Vector_Addition(a, b, c, n)
!!Verification
do i = 1, n
if (abs(c(i)-(a(i)+b(i)) == 0.00000)) then
else
print *, "FAIL"
endif
enddo
print *, "PASS"
! Delete the memory
deallocate(a)
deallocate(b)
deallocate(c)
end program main
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <assert.h>
#include <time.h>
#define N 5120
#define MAX_ERR 1e-6
// CPU function that adds two vector
float * Vector_Add(float *a, float *b, float *c, int n)
{
// ADD YOUR PARALLEL REGION FOR THE LOOP
for(int i = 0; i < n; i ++)
{
c[i] = a[i] + b[i];
}
return c;
}
int main()
{
// Initialize the variables
float *a, *b, *c;
// Allocate the memory
a = (float*)malloc(sizeof(float) * N);
b = (float*)malloc(sizeof(float) * N);
c = (float*)malloc(sizeof(float) * N);
// Initialize the arrays
for(int i = 0; i < N; i++)
{
a[i] = 1.0f;
b[i] = 2.0f;
}
// Start measuring time
clock_t start = clock();
// ADD YOUR PARALLEL REGION HERE
// Executing vector addition function
Vector_Add(a, b, c, N);
// Stop measuring time and calculate the elapsed time
clock_t end = clock();
double elapsed = (double)(end - start)/CLOCKS_PER_SEC;
printf("Time measured: %.3f seconds.\n", elapsed);
// Verification
for(int i = 0; i < N; i++)
{
assert(fabs(c[i] - a[i] - b[i]) < MAX_ERR);
}
printf("c[0] = %f\n", c[0]);
printf("PASSED\n");
// Deallocate the memory
free(a);
free(b);
free(c);
return 0;
}
module Vector_Addition_Mod
implicit none
contains
subroutine Vector_Addition(a, b, c, n)
use omp_lib
! Input vectors
real(8), intent(in), dimension(:) :: a
real(8), intent(in), dimension(:) :: b
real(8), intent(out), dimension(:) :: c
integer :: i, n
!! ADD YOUR PARALLEL DO LOOP
do i = 1, n
c(i) = a(i) + b(i)
end do
end subroutine Vector_Addition
end module Vector_Addition_Mod
program main
use Vector_Addition_Mod
implicit none
! Input vectors
real(8), dimension(:), allocatable :: a
real(8), dimension(:), allocatable :: b
! Output vector
real(8), dimension(:), allocatable :: c
! real(8) :: sum = 0
integer :: n, i
print *, "This program does the addition of two vectors "
print *, "Please specify the vector size = "
read *, n
! Allocate memory for vector
allocate(a(n))
allocate(b(n))
allocate(c(n))
! Initialize content of input vectors,
! vector a[i] = sin(i)^2 vector b[i] = cos(i)^2
do i = 1, n
a(i) = sin(i*1D0) * sin(i*1D0)
b(i) = cos(i*1D0) * cos(i*1D0)
enddo
!! ADD YOUR PARALLEL REGION
! Call the vector add subroutine
call Vector_Addition(a, b, c, n)
!!Verification
do i = 1, n
if (abs(c(i)-(a(i)+b(i)) == 0.00000)) then
else
print *, "FAIL"
endif
enddo
print *, "PASS"
! Delete the memory
deallocate(a)
deallocate(b)
deallocate(c)
end program main
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <assert.h>
#include <time.h>
#define N 5120 //500000000
#define MAX_ERR 1e-6
// CPU function that adds two vector
float * Vector_Add(float *a, float *b, float *c, int n)
{
// ADD YOUR PARALLEL
#pragma omp for
for(int i = 0; i < n; i ++)
{
c[i] = a[i] + b[i];
}
return c;
}
int main()
{
// Initialize the variables
float *a, *b, *c;
// Allocate the memory
a = (float*)malloc(sizeof(float) * N);
b = (float*)malloc(sizeof(float) * N);
c = (float*)malloc(sizeof(float) * N);
// Initialize the arrays
for(int i = 0; i < N; i++)
{
a[i] = 1.0f;
b[i] = 2.0f;
}
omp_set_num_threads(omp_get_max_threads());
// Start measuring time
double start = omp_get_wtime();
// Executing vector addition function
#pragma omp parallel
Vector_Add(a, b, c, N);
// Stop measuring time and calculate the elapsed time
double end = omp_get_wtime();
printf("Time measured: %.3f seconds.\n", end - start);
// Verification
for(int i = 0; i < N; i++)
{
assert(fabs(c[i] - a[i] - b[i]) < MAX_ERR);
}
printf("c[0] = %f\n", c[0]);
printf("PASSED\n");
// Deallocate the memory
free(a);
free(b);
free(c);
return 0;
}
module Vector_Addition_Mod
implicit none
contains
subroutine Vector_Addition(a, b, c, n)
use omp_lib
! Input vectors
real(8), intent(in), dimension(:) :: a
real(8), intent(in), dimension(:) :: b
real(8), intent(out), dimension(:) :: c
integer :: i, n
!$omp do
do i = 1, n
c(i) = a(i) + b(i)
end do
!$omp end do
end subroutine Vector_Addition
end module Vector_Addition_Mod
program main
use Vector_Addition_Mod
implicit none
! Input vectors
real(8), dimension(:), allocatable :: a
real(8), dimension(:), allocatable :: b
! Output vector
real(8), dimension(:), allocatable :: c
! real(8) :: sum = 0
integer :: n, i
print *, "This program does the addition of two vectors "
print *, "Please specify the vector size = "
read *, n
! Allocate memory for vector
allocate(a(n))
allocate(b(n))
allocate(c(n))
! Initialize content of input vectors,
! vector a[i] = sin(i)^2 vector b[i] = cos(i)^2
do i = 1, n
a(i) = sin(i*1D0) * sin(i*1D0)
b(i) = cos(i*1D0) * cos(i*1D0)
enddo
!$omp parallel
! Call the vector addition subroutine
call Vector_Addition(a, b, c, n)
!$omp end parallel
!!Verification
do i = 1, n
if (abs(c(i)-(a(i)+b(i)) == 0.00000)) then
else
print *, "FAIL"
endif
enddo
print *, "PASS"
! Delete the memory
deallocate(a)
deallocate(b)
deallocate(c)
end program main
Compilation and Output
Questions
- Can you measure the performance speedup for parallelising loop? Do you see any speedup?
- For example, can you create more threads to speed up the computation? If yer or not, why?