Matrix Multiplication
We will now look into basic matrix multiplication. In this tutorial, we will explore the process of matrix multiplication, a fundamental operation in linear algebra. Matrix multiplication is executed through a nested loop structure, which is a common approach for numerous computational tasks involving matrices. Mastering this example will provide valuable insight and practical experience in handling nested loops, a crucial skill for solving complex problems in future applications.
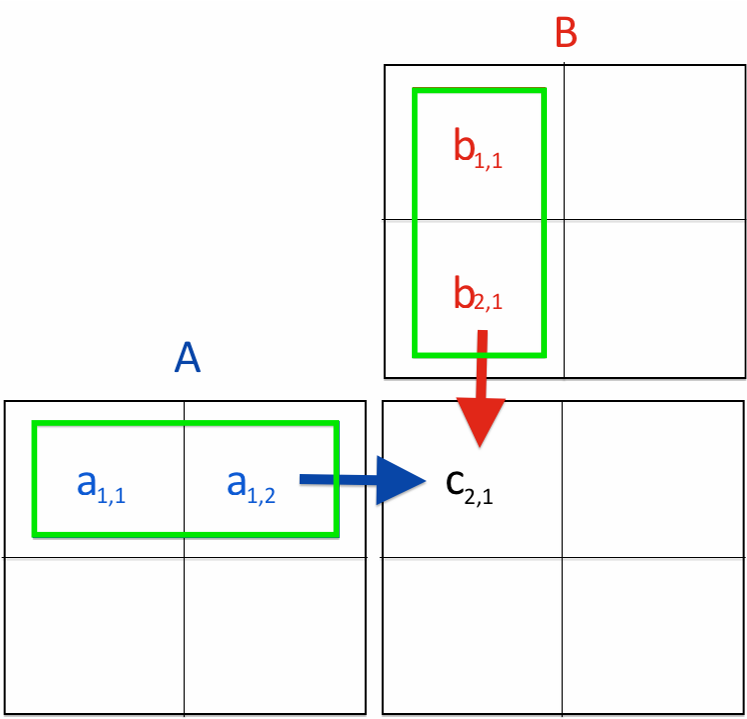
-
Allocating the CPU memory for A, B, and C matrices. Here, we notice that the matrix is stored in a 1D array because we want to consider the same function concept for CPU and GPU.
-
Allocating the GPU memory for A, B, and C matrices
-
Now, we need to fill in the values for the matrices A and B.
-
Transfer initialized A and B matrices from CPU to GPU
-
2D thread block for indexing x and y
-
Calling the kernel function
matrix multiplication function call
__global__ void matrix_mul(float* d_a, float* d_b, float* d_c, int width) { int row = blockIdx.x * blockDim.x + threadIdx.x; int col = blockIdx.y * blockDim.y + threadIdx.y; if ((row < width) && (col < width)) { float temp = 0; // each thread computes one // element of the block sub-matrix for (int i = 0; i < width; ++i) { temp += d_a[row*width+i]*d_b[i*width+col]; } d_c[row*width+col] = temp; } } -
Copy back computed value from GPU to CPU; transfer the data back to the GPU (from device to host). Here is the C matrix that contains the product of the two matrices.
-
Deallocate the host and device memory
Questions and Solutions¶
Examples: Matrix Multiplication
//-*-C++-*-
// Matrix-multiplication.cc
#include<iostream>
#include<cuda.h>
using namespace std;
float * matrix_mul(float *h_a, float *h_b, float *h_c, int width)
{
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float temp = 0;
for(int i = 0; i < width ; ++i)
{
temp += h_a[row*width+i] * h_b[i*width+col];
}
h_c[row*width+col] = temp;
}
}
return h_c;
}
int main()
{
cout << "Programme assumes that matrix (square matrix )size is N*N "<<endl;
cout << "Please enter the N size number "<< endl;
int N = 0;
cin >> N;
// Initialize the memory on the host
float *a, *b, *c;
// Allocate host memory
a = (float*)malloc(sizeof(float) * (N*N));
b = (float*)malloc(sizeof(float) * (N*N));
c = (float*)malloc(sizeof(float) * (N*N));
// Initialize host matrix
for(int i = 0; i < (N*N); i++)
{
a[i] = 1.0f;
b[i] = 2.0f;
}
// Device function call
matrix_mul(a, b, c, N);
// Verification
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
cout << c[j] <<" ";
}
cout << " " <<endl;
}
// Deallocate host memory
free(a);
free(b);
free(c);
return 0;
}
//-*-C++-*-
// Matrix-multiplication-template.cu
#include<iostream>
#include<cuda.h>
using namespace std;
__global__ void matrix_mul(float* d_a, float* d_b,
float* d_c, int width)
{
// create a 2d threads block
int row = ..................
int col = ....................
// only allow the threads that are needed for the computation
if (................................)
{
float temp = 0;
// each thread computes one
// element of the block sub-matrix
for (int i = 0; i < width; ++i)
{
temp += d_a[row*width+i]*d_b[i*width+col];
}
d_c[row*width+col] = temp;
}
}
// Host call (matrix multiplication)
float * cpu_matrix_mul(float *h_a, float *h_b, float *h_c, int width)
{
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float single_entry = 0;
for(int i = 0; i < width ; ++i)
{
single_entry += h_a[row*width+i] * h_b[i*width+col];
}
h_c[row*width+col] = single_entry;
}
}
return h_c;
}
int main()
{
cout << "Programme assumes that matrix (square matrix) size is N*N "<<endl;
cout << "Please enter the N size number "<< endl;
int N = 0;
cin >> N;
// Initialize the memory on the host
float *a, *b, *c, *host_check;
// Initialize the memory on the device
float *d_a, *d_b, *d_c;
// Allocate host memory
a = (float*)malloc(sizeof(float) * (N*N));
...
...
// Initialize host matrix
for(int i = 0; i < (N*N); i++)
{
a[i] = 2.0f;
b[i] = 2.0f;
}
// Allocate device memory
cudaMalloc((void**)&d_a, sizeof(float) * (N*N));
...
...
// Transfer data from a host to device memory
cudaMemcpy(.........................);
cudaMemcpy(.........................);
// Thread organization
int blockSize = ..............;
dim3 dimBlock(......................);
dim3 dimGrid(.......................);
// Device function call
matrix_mul<<<dimGrid,dimBlock>>>(d_a, d_b, d_c, N);
// Transfer data back to host memory
cudaMemcpy(c, d_c, sizeof(float) * (N*N), cudaMemcpyDeviceToHost);
// CPU computation for verification
cpu_matrix_mul(a,b,host_check,N);
// Verification
bool flag=1;
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
if(c[j*N+i]!= host_check[j*N+i])
{
flag=0;
break;
}
}
}
if (flag==0)
{
cout <<"Two matrices are not equal" << endl;
}
else
cout << "Two matrices are equal" << endl;
// Deallocate device memory
cudaFree...
// Deallocate host memory
free...
return 0;
}
//-*-C++-*-
// Matrix-multiplication.cu
#include<iostream>
#include<cuda.h>
using namespace std;
__global__ void matrix_mul(float* d_a, float* d_b,
float* d_c, int width)
{
int row = blockIdx.x * blockDim.x + threadIdx.x;
int col = blockIdx.y * blockDim.y + threadIdx.y;
if ((row < width) && (col < width))
{
float temp = 0;
// Each thread computes one
// Element of the block sub-matrix
for (int i = 0; i < width; ++i)
{
temp += d_a[row*width+i]*d_b[i*width+col];
}
d_c[row*width+col] = temp;
}
}
// Host call (matrix multiplication)
float * cpu_matrix_mul(float *h_a, float *h_b, float *h_c, int width)
{
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float single_entry = 0;
for(int i = 0; i < width ; ++i)
{
single_entry += h_a[row*width+i] * h_b[i*width+col];
}
h_c[row*width+col] = single_entry;
}
}
return h_c;
}
int main()
{
cout << "Programme assumes that matrix (square matrix) size is N*N "<<endl;
cout << "Please enter the N size number "<< endl;
int N = 0;
cin >> N;
// Initialize the memory on the host
float *a, *b, *c, *host_check;
// Initialize the memory on the device
float *d_a, *d_b, *d_c;
// Allocate host memory
a = (float*)malloc(sizeof(float) * (N*N));
b = (float*)malloc(sizeof(float) * (N*N));
c = (float*)malloc(sizeof(float) * (N*N));
host_check = (float*)malloc(sizeof(float) * (N*N));
// Initialize host matrix
for(int i = 0; i < (N*N); i++)
{
a[i] = 2.0f;
b[i] = 2.0f;
}
// Allocate device memory
cudaMalloc((void**)&d_a, sizeof(float) * (N*N));
cudaMalloc((void**)&d_b, sizeof(float) * (N*N));
cudaMalloc((void**)&d_c, sizeof(float) * (N*N));
// Transfer data from host to device memory
cudaMemcpy(d_a, a, sizeof(float) * (N*N), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, sizeof(float) * (N*N), cudaMemcpyHostToDevice);
// Thread organization
int blockSize = 32;
dim3 dimBlock(blockSize,blockSize,1);
dim3 dimGrid(ceil(N/float(blockSize)),ceil(N/float(blockSize)),1);
// Device function call
matrix_mul<<<dimGrid,dimBlock>>>(d_a, d_b, d_c, N);
// Transfer data back to host memory
cudaMemcpy(c, d_c, sizeof(float) * (N*N), cudaMemcpyDeviceToHost);
// CPU computation for verification
cpu_matrix_mul(a,b,host_check,N);
// Verification
bool flag=1;
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
if(c[j*N+i]!= host_check[j*N+i])
{
flag=0;
break;
}
}
}
if (flag==0)
{
cout <<"Two matrices are not equal" << endl;
}
else
cout << "Two matrices are equal" << endl;
// Deallocate device memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
// Deallocate host memory
free(a);
free(b);
free(c);
free(host_check);
return 0;
}
Compilation and Output
// compilation
$ g++ Matrix-multiplication.cc -o Matrix-Multiplication-CPU
// execution
$ ./Matrix-Multiplication-CPU
// output
$ g++ Matrix-multiplication.cc -o Matrix-multiplication
$ ./Matrix-multiplication
The programme assumes that the matrix (square matrix) size is N*N
Please enter the N size number
4
16 16 16 16
16 16 16 16
16 16 16 16
16 16 16 16
Questions
- Right now, we are using the 1D array to represent the matrix. However, you can also do it with the 2D matrix. Can you try 2D array matrix multiplication with a 2D thread block?
- Can you get the correct solution if you remove the
if ((row < width) && (col < width))condition from the__global__ void matrix_mul(float* d_a, float* d_b, float* d_c, int width)function? - Please try using different thread blocks and different matrix sizes.