Optimize Loops
Collapse Clause¶
The collapse clause is an important feature for optimizing nested loops in parallel computing. When applied, it allows the entire section of the iteration to be divided among the available number of threads. Specifically, if the number of iterations in the outer loop matches the number of available threads, the outer loop can be effectively divided based on the number of threads.
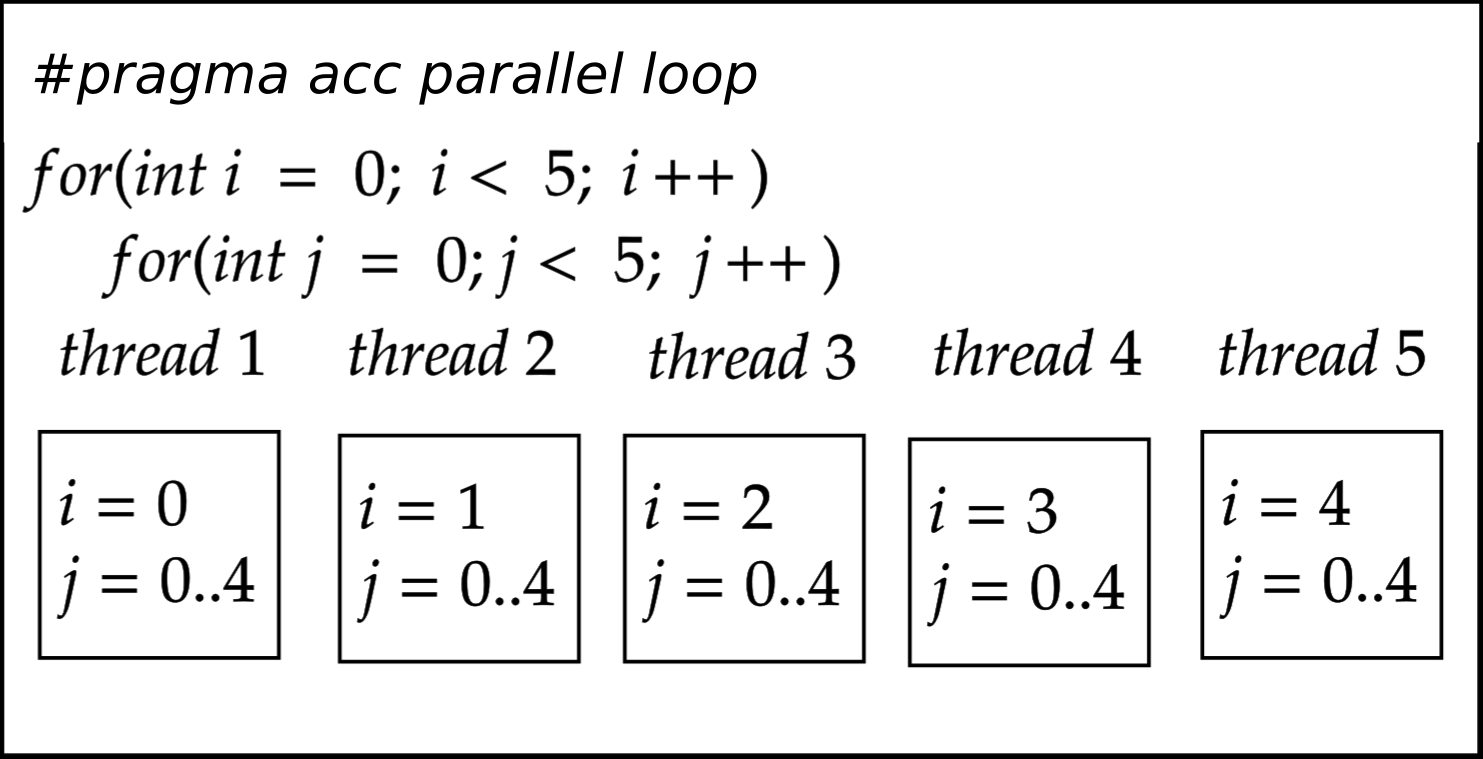
As illustrated in the figure below, without the use of the collapse clause, only the outer loop is parallelized. This means that each iteration of the outer loop will have a corresponding N number of inner loop executions, which is not the desired outcome for efficient parallel processing.
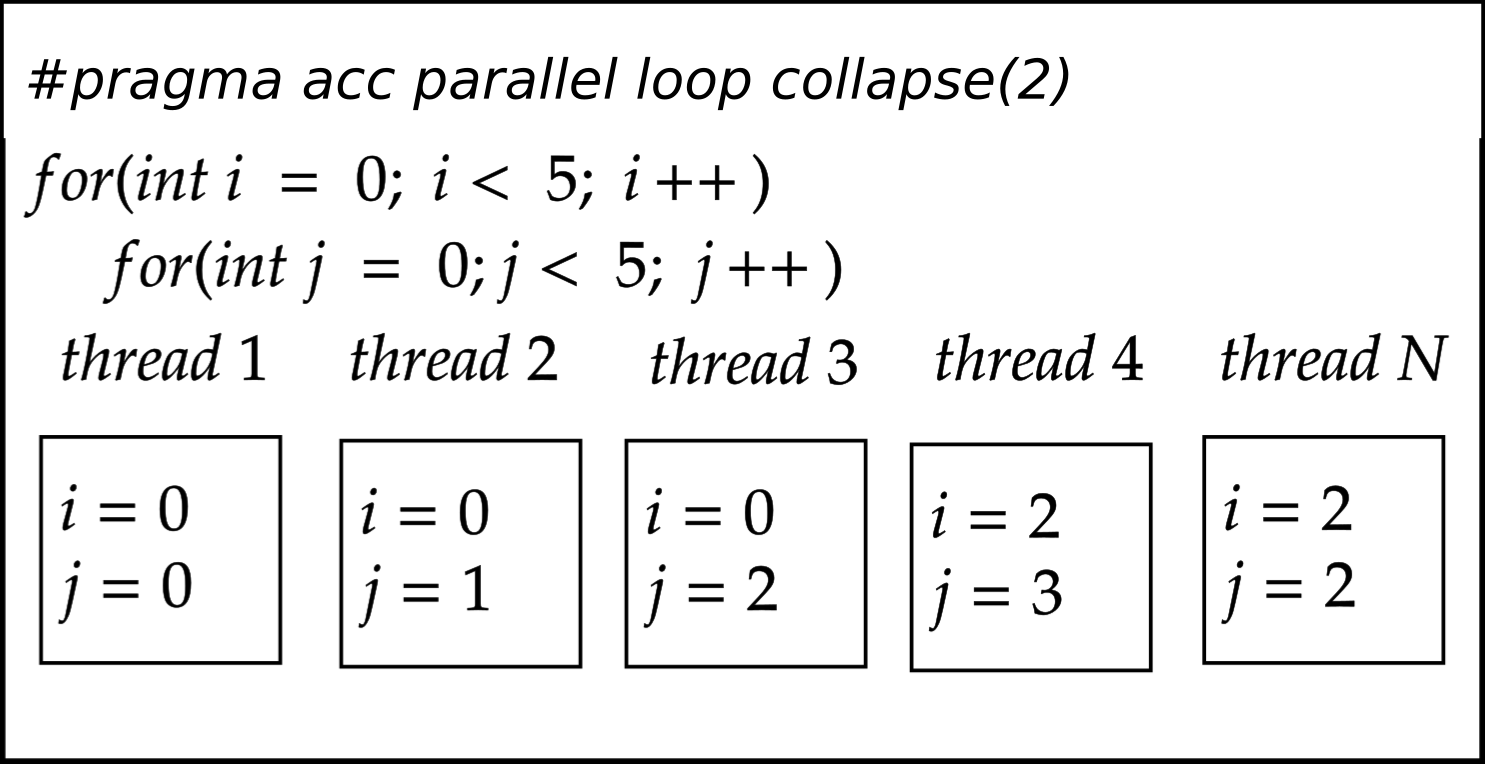
To optimize the utilization of threads, especially on GPUs with a higher number of threads available, such as the Nvidia A100 GPU, we implement the collapse clause. This adjustment enables all available threads to participate in executing every single iteration, as demonstrated in the figure below.
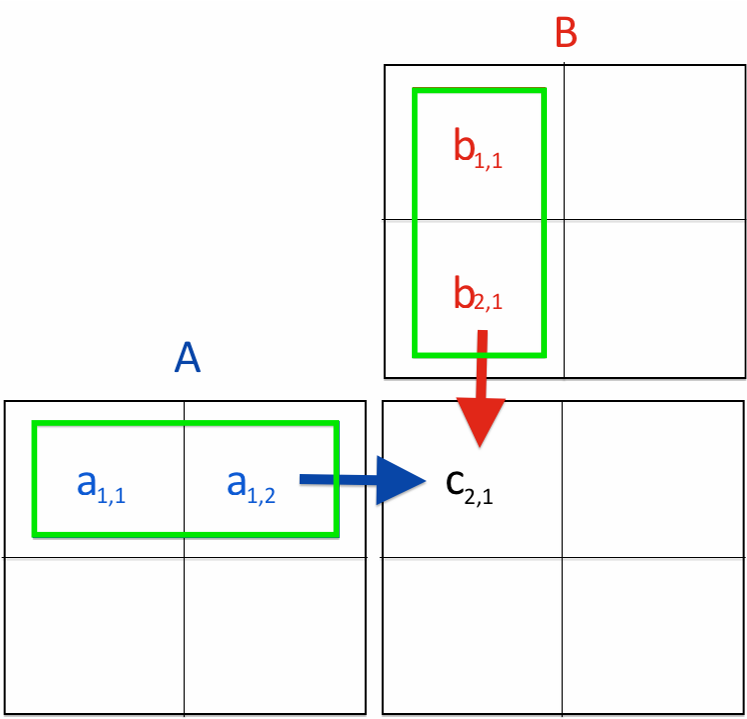
Next, we will examine a basic example of matrix multiplication, a computation that inherently relies on nested loops. Understanding this example will provide valuable insights into handling nested loops effectively, which is a common scenario in parallel computing.
-
Allocating the CPU memory for A, B, and C matrices. Here, we notice that the matrix is stored in a 1D array because we want to consider the same function concept for CPU and GPU.
-
Now, we need to fill in the values for the matrix A and B.
-
Calling function
matrix multiplication function call
void Matrix_Multiplication(float *restrict a, float *restrict b, float *restrict c, int width) { int length = width*width; float sum = 0; #pragma acc parallel copyin(a[0:(length)], b[0:(length)]) copyout(c[0:(length)]) #pragma acc loop collapse(2) reduction (+:sum) for(int row = 0; row < width ; ++row) { for(int col = 0; col < width ; ++col) { for(int i = 0; i < width ; ++i) { sum += a[row*width+i] * b[i*width+col]; } c[row*width+col] = sum; sum=0; } } } -
Deallocate the host memory
Questions and Solutions¶
Examples: Matrix Multiplication
#include<stdio.h>
#include<stdlib.h>
void Matrix_Multiplication(float *h_a, float *h_b, float *h_c, int width)
{
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float temp = 0;
for(int i = 0; i < width ; ++i)
{
temp += h_a[row*width+i] * h_b[i*width+col];
}
h_c[row*width+col] = temp;
}
}
}
int main()
{
printf("Programme assumes that matrix size is N*N \n");
printf("Please enter the N size number \n");
int N =0;
scanf("%d", &N);
// Initialize the memory on the host
float *a, *b, *c;
// Allocate host memory
a = (float*)malloc(sizeof(float) * (N*N));
b = (float*)malloc(sizeof(float) * (N*N));
c = (float*)malloc(sizeof(float) * (N*N));
// Initialize host matrix
for(int i = 0; i < (N*N); i++)
{
a[i] = 1.0f;
b[i] = 2.0f;
}
// Device function call
Matrix_Multiplication(a, b, c, N);
// Verification
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
printf("%f ", c[j]);
}
printf("%f ", c[j]);
}
// Deallocate host memory
free(a);
free(b);
free(c);
return 0;
}
#include<stdio.h>
#include<stdlib.h>
#include<openacc.h>
#include<stdbool.h>
void Matrix_Multiplication(float *restrict a, float *restrict b, float *restrict c, int width)
{
int length = width*width;
float sum = 0;
//#pragma acc ....
//#pragma acc ....
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
for(int i = 0; i < width ; ++i)
{
sum += a[row*width+i] * b[i*width+col];
}
c[row*width+col] = sum;
sum=0;
}
}
}
// Host call (matrix multiplication)
void CPU_Matrix_Multiplication(float *h_a, float *h_b, float *h_c, int width)
{
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float single_entry = 0;
for(int i = 0; i < width ; ++i)
{
single_entry += h_a[row*width+i] * h_b[i*width+col];
}
h_c[row*width+col] = single_entry;
}
}
}
int main()
{
printf("Programme assumes that matrix size is N*N \n");
printf("Please enter the N size number \n");
int N =0;
scanf("%d", &N);
// Initialize the memory on the host
float *a, *b, *c, *host_check;
// Initialize host matrix
for(int i = 0; i < (N*N); i++)
{
a[i] = 2.0f;
b[i] = 2.0f;
}
// Device function call
Matrix_Multiplication(a, b, c, N);
// CPU computation for verification
Matrix_Multiplication(a, b, host_check, N);
// Verification
bool flag=1;
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
if(c[j*N+i]!= host_check[j*N+i])
{
flag=0;
break;
}
}
}
if (flag==0)
printf("Two matrices are not equal\n");
else
printf("Two matrices are equal\n");
// Deallocate host memory
free...
return 0;
}
#include<stdio.h>
#include<stdlib.h>
#include<openacc.h>
#include<stdbool.h>
void Matrix_Multiplication(float *restrict a, float *restrict b, float *restrict c, int width)
{
int length = width*width;
float sum = 0;
#pragma acc parallel copyin(a[0:(length)], b[0:(length)]) copyout(c[0:(length)])
#pragma acc loop collapse(2) reduction (+:sum)
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
for(int i = 0; i < width ; ++i)
{
sum += a[row*width+i] * b[i*width+col];
}
c[row*width+col] = sum;
sum=0;
}
}
}
// Host call (matrix multiplication)
void CPU_Matrix_Multiplication(float *h_a, float *h_b, float *h_c, int width)
{
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float single_entry = 0;
for(int i = 0; i < width ; ++i)
{
single_entry += h_a[row*width+i] * h_b[i*width+col];
}
h_c[row*width+col] = single_entry;
}
}
}
int main()
{
cout << "Programme assumes that matrix (square matrix) size is N*N "<<endl;
cout << "Please enter the N size number "<< endl;
int N = 0;
cin >> N;
// Initialize the memory on the host
float *a, *b, *c, *host_check;
// Initialize the memory on the device
float *d_a, *d_b, *d_c;
// Allocate host memory
a = (float*)malloc(sizeof(float) * (N*N));
b = (float*)malloc(sizeof(float) * (N*N));
c = (float*)malloc(sizeof(float) * (N*N));
host_check = (float*)malloc(sizeof(float) * (N*N));
// Initialize host matrix
for(int i = 0; i < (N*N); i++)
{
a[i] = 2.0f;
b[i] = 2.0f;
}
// Device function call
Matrix_Multiplication(d_a, d_b, d_c, N);
// cpu computation for verification
CPU_Matrix_Multiplication(a,b,host_check,N);
// Verification
bool flag=1;
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
if(c[j*N+i]!= host_check[j*N+i])
{
flag=0;
break;
}
}
}
if (flag==0)
{
cout <<"Two matrices are not equal" << endl;
}
else
cout << "Two matrices are equal" << endl;
// Deallocate host memory
free(a);
free(b);
free(c);
free(host_check);
return 0;
}
Compilation and Output
// compilation
$ gcc Matrix-multiplication.c -o Matrix-Multiplication-CPU
// execution
$ ./Matrix-Multiplication-CPU
// output
$ g++ Matrix-multiplication.cc -o Matrix-multiplication
$ ./Matrix-multiplication
Programme assumes that the matrix (square matrix) size is N*N
Please enter the N size number
4
16 16 16 16
16 16 16 16
16 16 16 16
16 16 16 16
// compilation
$ nvcc -arch=compute_70 Matrix-multiplication.cu -o Matrix-Multiplication-GPU
Matrix_Multiplication:
9, Generating copyin(a[:length]) [if not already present]
Generating copyout(c[:length]) [if not already present]
Generating copyin(b[:length]) [if not already present]
Generating NVIDIA GPU code
12, #pragma acc loop gang collapse(2) /* blockIdx.x */
Generating reduction(+:sum)
14, /* blockIdx.x collapsed */
16, #pragma acc loop vector(128) /* threadIdx.x */
Generating implicit reduction(+:sum)
16, Loop is parallelizable
// execution
$ ./Matrix-Multiplication-GPU
The programme assumes that the matrix (square matrix) size is N*N
Please enter the N size number
$ 256
// output
$ Two matrices are equal
Thread Levels of Parallelism¶
By default, the compiler selects the most effective configuration of thread blocks necessary for computation. However, programmers have the ability to control these thread blocks within their applications. OpenACC offers clear directives that enable the manipulation of threads and thread blocks effectively.
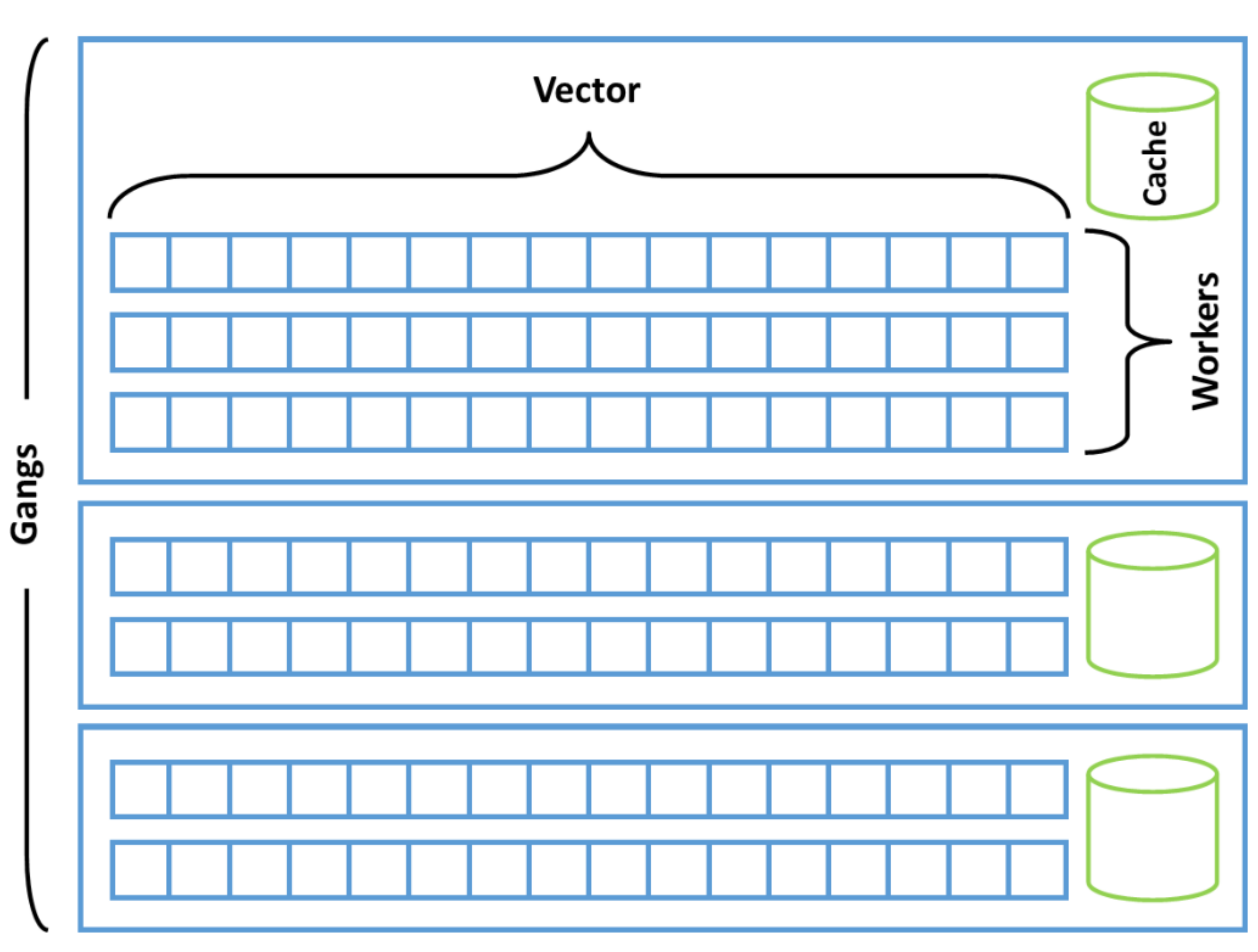
| OpenACC | CUDA | Parallelism |
|---|---|---|
| num_gangs | Grid Block | coarse |
| numn_workers | Warps | fine |
| vector_length | Threads | SIMD or vector |
This table illustrates the relationship between OpenACC and CUDA in terms of parallelism levels. Understanding these distinctions is crucial for optimizing performance in parallel computing.
Questions
- What happens to performance when you modify the values in
num_gangs(),num_workers(), andvector_length()compared to the default thread settings used by the compiler?