Shared Memory
In this tutorial, we will explore the concept of shared memory matrix multiplication. This technique involves partitioning the global matrix into smaller tiled matrices that are designed to fit into the shared memory of Nvidia GPUs. Utilizing shared memory is advantageous, as it offers significantly higher bandwidth compared to accessing global memory, thereby enhancing performance in computational tasks.

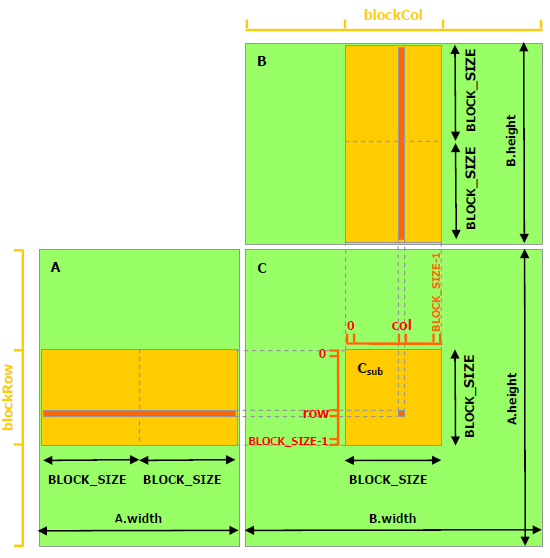
- This is very similar to the previous example; however, we just need to allocate the small block matrix into shared memory. The example below shows the blocking size for
aandbmatrices, respectively, for globalAandBmatrices.
- Then, we need to iterate elements within the block size and, finally, with the global index. These can be achieved with CUDA threads.
-
You can also increase the shared memory or L1 cache size by using
cudaFuncSetCacheConfig. For more information about CUDA API, please refer to cudaFuncSetCacheConfig.Tips
cudaFuncSetCacheConfig(kernel, cudaFuncCachePreferL1); //cudaFuncSetCacheConfig(kernel, cudaFuncCachePreferShared); cudaFuncCachePreferNone: no preference for shared memory or L1 (default) cudaFuncCachePreferShared: prefer larger shared memory and smaller L1 cache cudaFuncCachePreferL1: prefer larger L1 cache and smaller shared memory cudaFuncCachePreferEqual: prefer equal size L1 cache and shared memory // simple example usage increasing more shared memory #include<stdio.h> int main() { // example of increasing the shared memory cudaDeviceSetCacheConfig(My_Kernel, cudaFuncCachePreferShared); My_Kernel<<<>>>(); cudaDeviceSynchronize(); return 0; } -
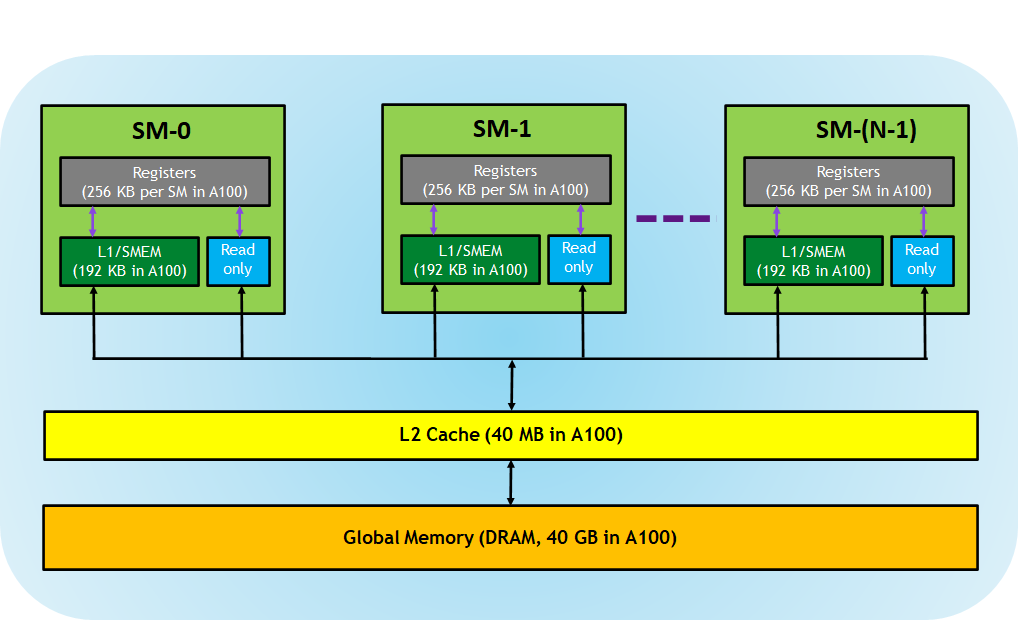
Different Nvidia GPUs provide different configurations; for example, Ampere GA102 GPU Architecture will support the following configuration:
Questions and Solutions¶
Example: Shared Memory - Matrix Multiplication
// Matrix-multiplication-shared-template.cu
//-*-C++-*-
#include<iostream>
#include<cuda.h>
// block size for the matrix
#define BLOCK_SIZE 16
using namespace std;
// Device call (matrix multiplication)
__global__ void matrix_mul(const float *d_a, const float *d_b,
float *d_c, int width)
{
// Shared memory allocation for the block matrix
__shared__ int a_block[BLOCK_SIZE][BLOCK_SIZE];
...
// Indexing for the block matrix
int tx = threadIdx.x;
...
// Indexing global matrix to block matrix
int row = threadIdx.x+blockDim.x*blockIdx.x;
...
// Allow threads only for the size of rows and columns (we assume square matrix)
if ((row < width) && (col< width))
{
// Save temporary value for the particular index
float temp = 0;
for(int i = 0; i < width / BLOCK_SIZE; ++i)
{
// Allign the global matrix to the block matrix
a_block[ty][tx] = d_a[row * width + (i * BLOCK_SIZE + tx)];
b_block[ty][tx] = d_b[(i * BLOCK_SIZE + ty) * width + col];
// Make sure all the threads are synchronized
....
// Multiply the block matrix
for(int j = 0; j < BLOCK_SIZE; ++j)
{
temp += a_block[ty][j] * b_block[j][tx];
}
// Make sure all the threads are synchronized
...
}
// Save block matrix entry to the global matrix
...
}
}
// Host call (matrix multiplication)
float * cpu_matrix_mul(float *h_a, float *h_b, float *h_c, int width)
{
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float temp = 0;
for(int i = 0; i < width ; ++i)
{
temp += h_a[row*width+i] * h_b[i*width+col];
}
h_c[row*width+col] = temp;
}
}
return h_c;
}
int main()
{
cout << "Programme assumes that matrix size is N*N "<<endl;
cout << "Matrix dimensions are assumed to be multiples of BLOCK_SIZE=16" << endl;
cout << "Please enter the N size number "<< endl;
int N=0;
cin >> N;
// Initialize the memory on the host
float *a, *b, *c, *host_check;
// Initialize the memory on the device
float *d_a, *d_b, *d_c;
// Allocate host memory
a = (float*)malloc(sizeof(float) * (N*N));
b = (float*)malloc(sizeof(float) * (N*N));
c = (float*)malloc(sizeof(float) * (N*N));
host_check = (float*)malloc(sizeof(float) * (N*N));
// Initialize host arrays
for(int i = 0; i < (N*N); i++)
{
a[i] = 2.0f;
b[i] = 2.0f;
}
// Allocate device memory
cudaMalloc((void**)&d_a, sizeof(float) * (N*N));
cudaMalloc((void**)&d_b, sizeof(float) * (N*N));
cudaMalloc((void**)&d_c, sizeof(float) * (N*N));
// Transfer data from host to device memory
cudaMemcpy(d_a, a, sizeof(float) * (N*N), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, sizeof(float) * (N*N), cudaMemcpyHostToDevice);
cudaMemcpy(d_c, c, sizeof(float) * (N*N), cudaMemcpyHostToDevice);
// Thread organization
dim3 Block_dim(BLOCK_SIZE, BLOCK_SIZE, 1);
...
// Device function call
matrix_mul<<<Grid_dim, Block_dim>>>(d_a, d_b, d_c, N);
// Transfer data back to host memory
cudaMemcpy(c, d_c, sizeof(float) * (N*N), cudaMemcpyDeviceToHost);
// Cpu computation for verification
cpu_matrix_mul(a,b,host_check,N);
// Verification
bool flag=1;
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
if(c[j*N+i]!= host_check[j*N+i])
{
flag=0;
break;
}
}
}
if (flag==0)
{
cout <<"But, two matrices are not equal" << endl;
cout <<"Matrix dimensions are assumed to be multiples of BLOCK_SIZE=16" << endl;
}
else
cout << "Two matrices are equal" << endl;
// Deallocate device memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
// Deallocate host memory
free(a);
free(b);
free(c);
free(host_check);
return 0;
}
// Matrix-multiplication-shared.cu
//-*-C++-*-
#include<iostream>
#include<cuda.h>
// block size for the matrix
#define BLOCK_SIZE 16
using namespace std;
// Device call (matrix multiplication)
__global__ void matrix_mul(const float *d_a, const float *d_b,
float *d_c, int width)
{
// Shared memory allocation for the block matrix
__shared__ int a_block[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int b_block[BLOCK_SIZE][BLOCK_SIZE];
// Indexing for the block matrix
int tx = threadIdx.x;
int ty = threadIdx.y;
// Indexing global matrix to block matrix
int row = threadIdx.x+blockDim.x*blockIdx.x;
int col = threadIdx.y+blockDim.y*blockIdx.y;
// Allow threads only for the size of rows and columns (we assume square matrix)
if ((row < width) && (col< width))
{
// Save temporary value for the particular index
float temp = 0;
for(int i = 0; i < width / BLOCK_SIZE; ++i)
{
// Allign the global matrix to the block matrix
a_block[ty][tx] = d_a[row * width + (i * BLOCK_SIZE + tx)];
b_block[ty][tx] = d_b[(i * BLOCK_SIZE + ty) * width + col];
// Make sure all the threads are synchronized
__syncthreads();
// Multiply the block matrix
for(int j = 0; j < BLOCK_SIZE; ++j)
{
temp += a_block[ty][j] * b_block[j][tx];
}
__syncthreads();
}
// Save block matrix entry to the global matrix
d_c[row*width+col] = temp;
}
}
// Host call (matrix multiplication)
float * cpu_matrix_mul(float *h_a, float *h_b, float *h_c, int width)
{
for(int row = 0; row < width ; ++row)
{
for(int col = 0; col < width ; ++col)
{
float single_entry = 0;
for(int i = 0; i < width ; ++i)
{
single_entry += h_a[row*width+i] * h_b[i*width+col];
}
h_c[row*width+col] = single_entry;
}
}
return h_c;
}
int main()
{
cout << "Programme assumes that matrix size is N*N "<<endl;
cout << "Matrix dimensions are assumed to be multiples of BLOCK_SIZE=16" << endl;
cout << "Please enter the N size number "<< endl;
int N=0;
cin >> N;
// Initialize the memory on the host
float *a, *b, *c, *host_check;
// Initialize the memory on the device
float *d_a, *d_b, *d_c;
// Allocate host memory
a = (float*)malloc(sizeof(float) * (N*N));
b = (float*)malloc(sizeof(float) * (N*N));
c = (float*)malloc(sizeof(float) * (N*N));
host_check = (float*)malloc(sizeof(float) * (N*N));
// Initialize host arrays
for(int i = 0; i < (N*N); i++)
{
a[i] = 2.0f;
b[i] = 2.0f;
}
// Allocate device memory
cudaMalloc((void**)&d_a, sizeof(float) * (N*N));
cudaMalloc((void**)&d_b, sizeof(float) * (N*N));
cudaMalloc((void**)&d_c, sizeof(float) * (N*N));
// Transfer data from host to device memory
cudaMemcpy(d_a, a, sizeof(float) * (N*N), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, sizeof(float) * (N*N), cudaMemcpyHostToDevice);
cudaMemcpy(d_c, c, sizeof(float) * (N*N), cudaMemcpyHostToDevice);
// Thread organization
dim3 Block_dim(BLOCK_SIZE, BLOCK_SIZE, 1);
dim3 Grid_dim(ceil(N/BLOCK_SIZE), ceil(N/BLOCK_SIZE), 1);
// Device function call
matrix_mul<<<Grid_dim, Block_dim>>>(d_a, d_b, d_c, N);
// Transfer data back to host memory
cudaMemcpy(c, d_c, sizeof(float) * (N*N), cudaMemcpyDeviceToHost);
// CPU computation for verification
cpu_matrix_mul(a,b,host_check,N);
// Verification
bool flag=1;
for(int i = 0; i < N; i++)
{
for(int j = 0; j < N; j++)
{
if(c[j*N+i]!= host_check[j*N+i])
{
flag=0;
break;
}
}
}
if (flag==0)
{
cout <<"But, two matrices are not equal" << endl;
cout <<"Matrix dimensions are assumed to be multiples of BLOCK_SIZE=16" << endl;
}
else
cout << "Two matrices are equal" << endl;
// Deallocate device memory
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
// Deallocate host memory
free(a);
free(b);
free(c);
free(host_check);
return 0;
}
Compilation and Output
// compilation
$ nvcc -arch=sm_70 Matrix-multiplication-shared.cu -o Matrix-multiplication-shared
// execution
$ ./Matrix-multiplication-shared
The programme assumes that the matrix size is N*N
Matrix dimensions are assumed to be multiples of BLOCK_SIZE=16
Please enter the N size number
$ 256
// output
$ Two matrices are equal
Questions
- Could you resize the
BLOCK_SIZEnumber and check the solution's correctness? - Can you also create a different kind of thread block and matrix size, and check the solution's correctness?
- Please try using
cudaFuncSetCacheConfigand check if you can successfully execute the application.
Last update: June 28, 2025 20:20:06
Created: March 11, 2023 20:16:27
Created: March 11, 2023 20:16:27