Unified Memory
Unified memory simplifies the explicit data movement from the host to the device for programmers. The OpenACC API automatically manages data transfer between the CPU and the GPU. In this example, we will explore vector addition on the GPU utilizing the unified memory concept.
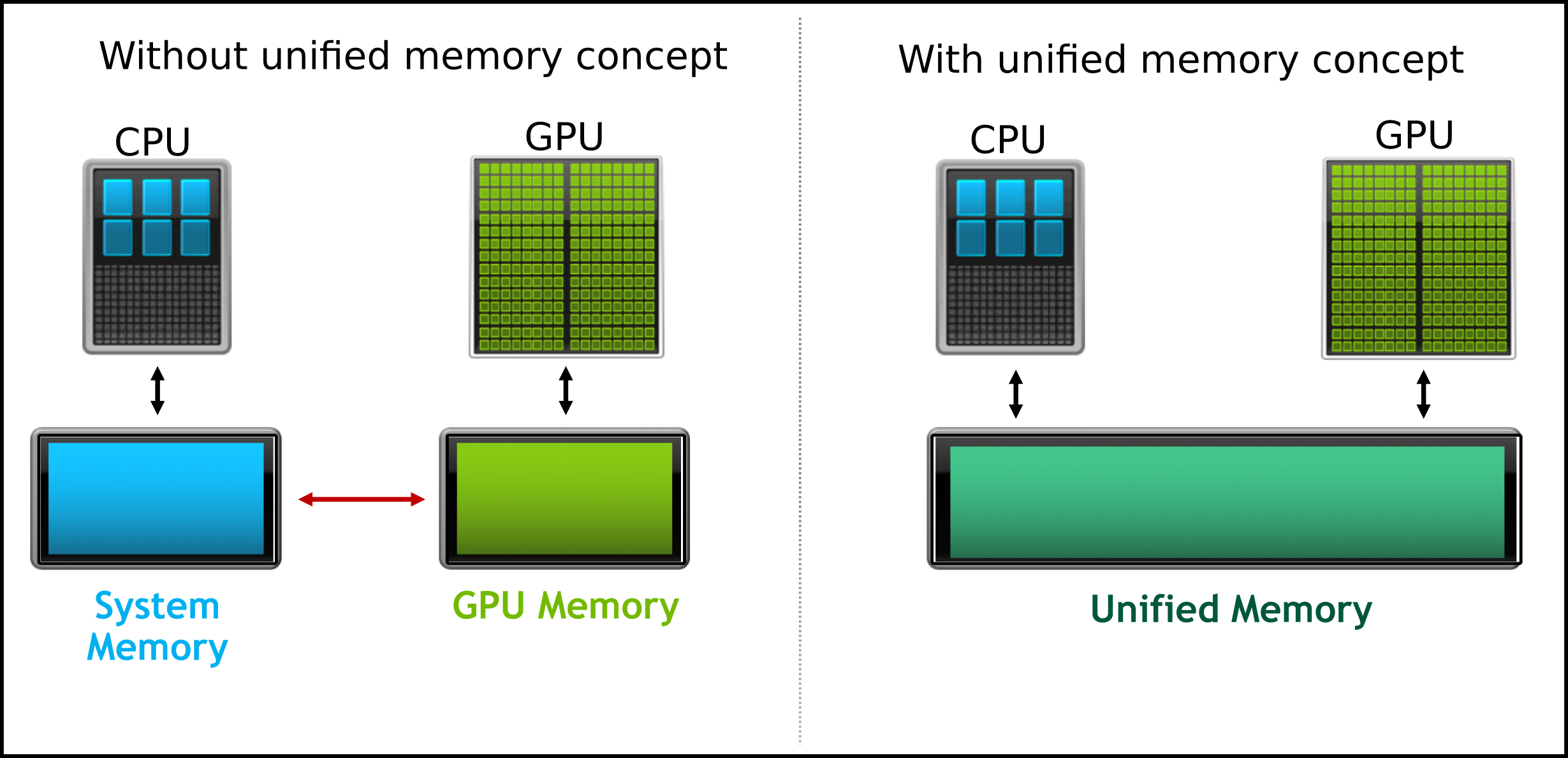
To enable unified memory in OpenACC, it is sufficient to use the compiler flag -gpu=managed.
The following table summarizes the required steps for implementing the unified memory concept:
Unified Memory
| Without unified memory | With unified memory |
|---|---|
| Allocate the host memory | Allocate the host memory |
| Initialize the host value | Initialize the host value |
| Use data cluases, e.g,. copy, copyin | |
| Do the computation using the GPU kernel | Do the computation using the GPU kernel |
| Free host memory | Free host memory |
Questions and Solutions¶
Examples: Vector Addition
// Vector-addition-template.c
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <assert.h>
#include <time.h>
#include <openacc.h>
#define N 5120
#define MAX_ERR 1e-6
// GPU function that adds two vectors
// function that adds two vector
void Vector_Addition(float *restrict a, float *restrict b, float *restrict c, int n)
{
// add here either parallel or kernel and do need to add data map clauses
#pragma acc
for(int i = 0; i < n; i ++)
{
c[i] = a[i] + b[i];
}
}
int main()
{
// Initialize the memory on the host
float *restrict a, *restrict b, *restrict c;
// Allocate host memory
a = (float*)malloc(sizeof(float) * N);
b = (float*)malloc(sizeof(float) * N);
c = (float*)malloc(sizeof(float) * N);
// Initialize host arrays
for(int i = 0; i < N; i++)
{
a[i] = 1.0f;
b[i] = 2.0f;
}
// Start measuring time
clock_t start = clock();
// Executing CPU function
Vector_Addition(a, b, c, N);
// Stop measuring time and calculate the elapsed time
clock_t end = clock();
double elapsed = (double)(end - start)/CLOCKS_PER_SEC;
printf("Time measured: %.3f seconds.\n", elapsed);
// Verification
for(int i = 0; i < N; i++)
{
assert(fabs(c[i] - a[i] - b[i]) < MAX_ERR);
}
printf("PASSED\n");
// Deallocate host memory
free(a);
free(b);
free(c);
return 0;
}
// Vector-addition-openacc.c
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <assert.h>
#include <time.h>
#include <openacc.h>
#define N 5120
#define MAX_ERR 1e-6
// function that adds two vector
void Vector_Addition(float *restrict a, float *restrict b, float *restrict c, int n)
{
#pragma acc kernels loop
for(int i = 0; i < n; i ++)
{
c[i] = a[i] + b[i];
}
}
int main()
{
// Initialize the memory on the host
float *restrict a, *restrict b, *restrict c;
// Allocate host memory
a = (float*)malloc(sizeof(float) * N);
b = (float*)malloc(sizeof(float) * N);
c = (float*)malloc(sizeof(float) * N);
// Initialize host arrays
for(int i = 0; i < N; i++)
{
a[i] = 1.0f;
b[i] = 2.0f;
}
// Start measuring time
clock_t start = clock();
// Executing CPU function
Vector_Addition(a, b, c, N);
// Stop measuring time and calculate the elapsed time
clock_t end = clock();
double elapsed = (double)(end - start)/CLOCKS_PER_SEC;
printf("Time measured: %.3f seconds.\n", elapsed);
// Verification
for(int i = 0; i < N; i++)
{
assert(fabs(c[i] - a[i] - b[i]) < MAX_ERR);
}
printf("PASSED\n");
// Deallocate host memory
free(a);
free(b);
free(c);
return 0;
}
!! Vector-addition-openacc.f90
module Vector_Addition_Mod
implicit none
contains
subroutine Vector_Addition(a, b, c, n)
! Input vectors
real(8), intent(in), dimension(:) :: a
real(8), intent(in), dimension(:) :: b
real(8), intent(out), dimension(:) :: c
integer :: i, n
// add here your acc directive
do i = 1, n
c(i) = a(i) + b(i)
end do
!$acc.....
end subroutine Vector_Addition
end module Vector_Addition_Mod
program main
use openacc
use Vector_Addition_Mod
implicit none
! Input vectors
real(8), dimension(:), allocatable :: a
real(8), dimension(:), allocatable :: b
! Output vector
real(8), dimension(:), allocatable :: c
integer :: n, i
print *, "This program does the addition of two vectors "
print *, "Please specify the vector size = "
read *, n
! Allocate memory for vector
allocate(a(n))
allocate(b(n))
allocate(c(n))
! Initialize content of input vectors,
! vector a[i] = sin(i)^2 vector b[i] = cos(i)^2
do i = 1, n
a(i) = sin(i*1D0) * sin(i*1D0)
b(i) = cos(i*1D0) * cos(i*1D0)
enddo
! Call the vector add subroutine
call Vector_Addition(a, b, c, n)
!!Verification
do i = 1, n
if (abs(c(i)-(a(i)+b(i))==0.00000)) then
else
print *, "FAIL"
endif
enddo
print *, "PASS"
! Delete the memory
deallocate(a)
deallocate(b)
deallocate(c)
end program main
!! Vector-addition-openacc.f90
module Vector_Addition_Mod
implicit none
contains
subroutine Vector_Addition(a, b, c, n)
! Input vectors
real(8), intent(in), dimension(:) :: a
real(8), intent(in), dimension(:) :: b
real(8), intent(out), dimension(:) :: c
integer :: i, n
!$acc parallel loop
do i = 1, n
c(i) = a(i) + b(i)
end do
!$acc end parallel
end subroutine Vector_Addition
end module Vector_Addition_Mod
program main
use openacc
use Vector_Addition_Mod
implicit none
! Input vectors
real(8), dimension(:), allocatable :: a
real(8), dimension(:), allocatable :: b
! Output vector
real(8), dimension(:), allocatable :: c
integer :: n, i
print *, "This program does the addition of two vectors "
print *, "Please specify the vector size = "
read *, n
! Allocate memory for vector
allocate(a(n))
allocate(b(n))
allocate(c(n))
! Initialize content of input vectors,
! vector a[i] = sin(i)^2 vector b[i] = cos(i)^2
do i = 1, n
a(i) = sin(i*1D0) * sin(i*1D0)
b(i) = cos(i*1D0) * cos(i*1D0)
enddo
! Call the vector add subroutine
call Vector_Addition(a, b, c, n)
!!Verification
do i = 1, n
if (abs(c(i)-(a(i)+b(i))==0.00000)) then
else
print *, "FAIL"
endif
enddo
print *, "PASS"
! Delete the memory
deallocate(a)
deallocate(b)
deallocate(c)
end program main
Compilation and Output
// compilation
$ nvc -fast -acc=gpu -gpu=cc80 -Minfo=accel -gpu=managed Vector-addition-openacc.c -o Vector-Addition-GPU
Vector_Addition:
12, Generating copyin(a[:n]) [if not already present]
Generating copyout(c[:n]) [if not already present]
Generating copyin(b[:n]) [if not already present]
14, Loop is parallelizable
Generating NVIDIA GPU code
14, #pragma acc loop gang, vector(128) /* blockIdx.x threadIdx.x */
// execution
$ ./Vector-Addition-GPU
// output
$ ./Vector-addition-GPU
PASSED
// compilation
$ nvfortran -fast -acc=gpu -gpu=cc80 -gpu=managed -Minfo=accel Vector-addition-openacc.f90 -o Vector-Addition-GPU
vector_addition:
12, Generating NVIDIA GPU code
13, !$acc loop gang, vector(128) ! blockidx%x threadidx%x
12, Generating implicit copyin(a(:n)) [if not already present]
Generating implicit copyout(c(:n)) [if not already present]
Generating implicit copyin(b(:n)) [if not already present
// execution
$ ./Vector-Addition-GPU
// output
This program does the addition of two vectors
Please specify the vector size =
1000000
PASS
Questions
- Have you noticed any performance improvements when using unified memory?
Last update: March 24, 2025 00:31:58
Created: September 18, 2023 16:21:20
Created: September 18, 2023 16:21:20