Work Sharing Constructs(loop-scheduling)
Loop scheduling¶
However, the above example is very simple. Because, in most cases, we would end up doing a large list of arrays with complex computations within the loop. Therefore, the workloading should be optimally distributed among the threads in those cases. To handle those considerations, OpenMP has provided the following loop-sharing clauses. They are: Static, Dynamic, Guided, Auto, and Runtime.
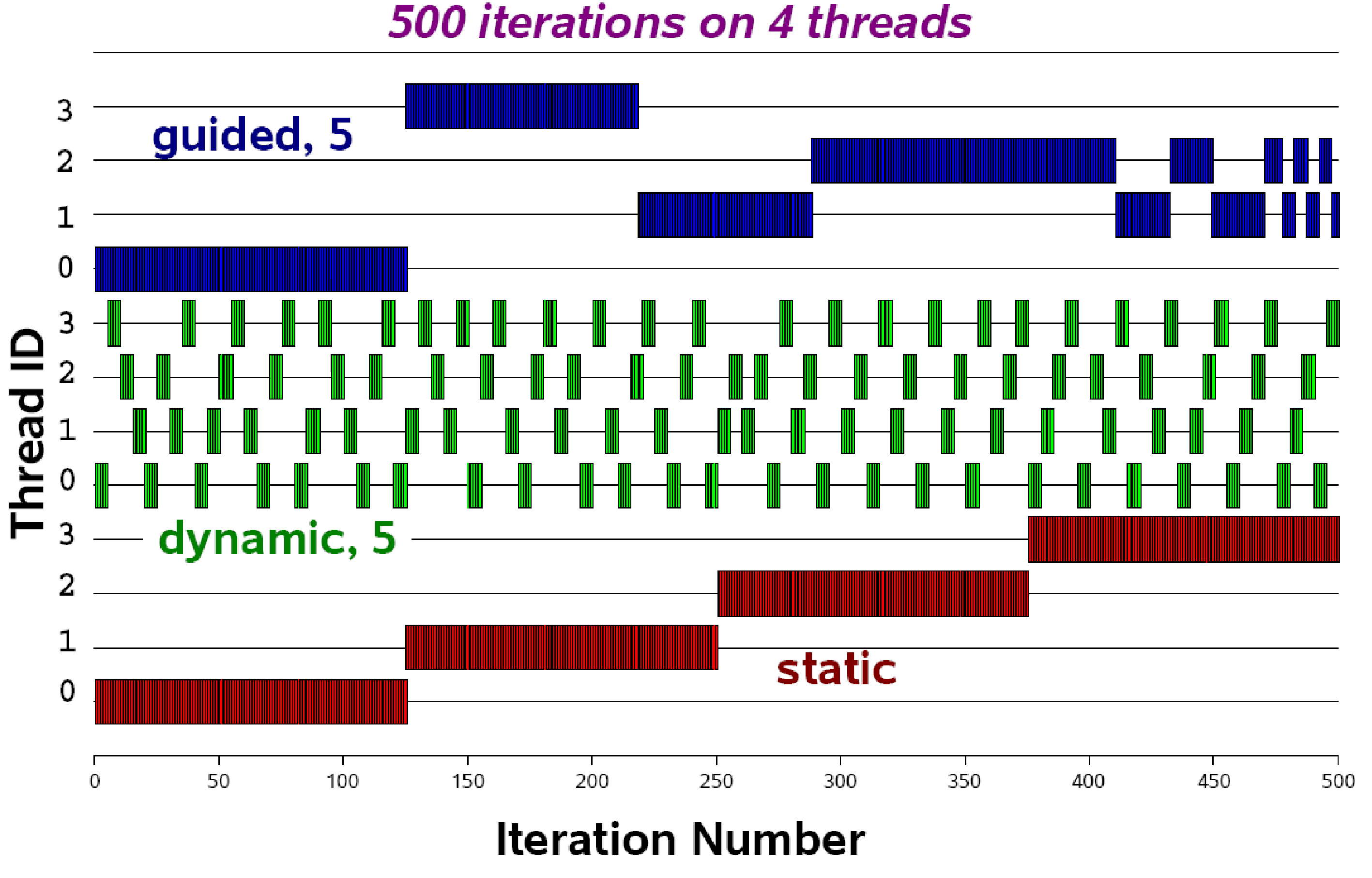
Example - Loop scheduling clauses
Static¶
- The number of iterations are divided by chunksize.
- If the chunksize is not provided, a number of iterations will be divided by the size of the team of threads.
- e.g., n=100, numthreads=5; each thread will execute the 20 iterations in parallel.
- This is useful when the computational cost is similar to each iteration.
Examples and Question: static
- What happens if you would set the chunksize, for example,
schedule(static,4)? What do you notice?
Dynamic¶
- The number of iterations are divided by chunksize.
- If the chunksize is not provided, the default value will be considered 1.
- This is useful when the computational cost is different in the iteration.
- This will quickly place the chunk of data in the queue.
Examples and Question: dynamic
- What happens if you would set the chunksize, for example, schedule(dynamic,4)? What do you notice?
- Do you notice if the iterations are divided by the chunksize that we set?
Guided¶
- Similar to dynamic scheduling, the number of iterations are divided by chunksize.
- But the chunk of the data size is decreasing, which is proportional to the number of unsigned iterations divided by the number of threads.
- If the chunksize is not provided, the default value will be considered 1.
- This is useful when there is poor load balancing at the end of the iteration.
Examples and Question: guided
- Are there any differences between
autoandguidedordynamic?
Auto¶
- Here the compiler chooses the best combination of the chunksize to be used.
Examples and Question: auto
- What would you choose for your application, auto, dynamic, guided, or static? If you are going to choose either one of them, then have a valid reason.
Runtime¶
- During the compilation, we simply set the loop scheduling concept.